In confidential computing, remote attestation provides a way of proving what workload an enclave or confidential virtual machine (CVM) is running, but attestation alone is not sufficient for a verifier to know they are communicating with the author of that proof. The solution is to create an association or ‘binding’ between the attestation and a secure channel by including some associated data as signed input to the attestation.
Since TLS is the prevalent protocol for authenticated private communication on the Internet, many remote-attested TLS protocols have been proposed, with widely varying approaches as to what the input data should be and at what point the attestation evidence is signed and transmitted.
An important distinction is whether attestation is bound to an identity which is then authenticated on the secure channel, or to the secure channel itself. The latter has notable security advantages which are discussed more in ‘The Evolution of Remote Attested TLS’. This caused us to initially switch from a certificate binding-based protocol (Edgeless Systems’ aTLS) to session binding using Exported Keying Material (EKM) from the TLS session.
This post is the next chapter in our remote-attested TLS journey. We discuss the limitations we found with TLS session binding, and why it is not a good fit for large, latency-sensitive CVM deployments. We then introduce our new protocol which combines a the original certificate-binding approach with conventional CA-endorsed TLS.
Where session binding shines and where it doesn’t
Switching to EKM-bound attestation had several advantages over embedding attestation in a certificate extension.
Firstly, we could use Certificate Authority (CA) signed certificates - which was not possible with the protocol we used before as most CAs will not sign certificates with custom extensions.
Secondly, attestation evidence was guaranteed to be fresh, unique to the session, and kept private. The exported key material is derived from the session key, which contains ephemeral DH secret, meaning an attestation from a previous session cannot be replayed, even if the remote party is able to produce a signature with the TLS key, they must also produce a fresh attestation in order to authenticate. Furthermore since the attestation is transmitted as application data post handshake, all the security and authenticity guarantees of TLS apply.
This turned out to be good for security but can be bad for performance. Producing and verifying fresh attestation evidence for every TLS session makes sense for some use-cases. But what if we want to have many concurrent sessions to get maximum throughput?
TDX Attestation generation is slow and serial

We benchmarked TDX attestation generation on Google Cloud Platform (GCP) and found it generally takes around 39ms. This is already very slow, but what’s worse is that it will not parallelize at all. Requesting two attestations concurrently takes almost exactly double the time it takes to generate a single attestation. This is surprising. We know that evidence signing is serialized through a single quoting enclave, meaning attestation requests from all TDX guests on a particular host must wait in line for their turn to have evidence signed. But our expectation was that there are some parts of the quote generation process which can be parallelized, so requesting five quotes concurrently will still be faster than requesting five quotes one after the other. But this is unfortunately not the case on GCP.
TDX attestation verification on the other hand can be made to be very fast. We need to do a network call to get collateral for the verification, but this can be cached, and subsequent verifications only involve local parsing and signature verification, and take only around 0.5ms.
By binding attestation to a TLS session via EKM, we have to wait for a fresh attestation for every connection we establish. This is fine when we have a single, long-lived connection between two hosts. But if we want to quickly establish many concurrent connections to maximize throughput, the price we pay for each subsequent connection gets higher as our attestation requests pile up into a queue.
ACME is slow and requires co-operation from a third party
By using CA-signed TLS certificates we give the client a little extra assurance that the domain name owner has chosen to endorse the endpoint they are connecting to. Even stronger, CAA records can be used to bind a domain to a specific ACME account inside the trust domain (TD). This is discussed further in ‘The Evolution of Remote Attested TLS’.
But there’s a catch. ACME can be slow and relies on the cooperation of a third party at CVM boot. If we want to confine the ACME account and/or TLS private key to the TD, the CA needs to sign a new certificate every time the CVM boots.
Regardless of whether HTTP-01, TLS-ALPN-01, or DNS-01 challenges are used, certificate issuance depends on successful interaction with external infrastructure and the CA. Failures in DNS propagation, challenge validation, CA availability, or rate limits can prevent a freshly booted CVM from becoming operational.
This is particularly concerning when we have multiple instances of a service and need to reboot all of them with a new OS image following a fix. Any issue with CAs or the ACME protocol at this point would stop the whole network from functioning.
There is no one-size-fits-all protocol
While TLS session binding makes sense for some use-cases, for others the performance cost outweighs the security advantage. For connections between Buildernet nodes to Builder Hub, we want to frequently exchange small payloads such as the details of the current peer set. This can be done in a single long-lived connection so one attestation-per-session is acceptable.
However, in developing a MEV-boost equivalent marketplace for searchers in TDX, we encountered the need to be able to send a large amount of transaction data over attested channels, to multiple CVM instances, as fast as possible. This meant opening many concurrent TCP connections, doing a lot of handshakes, and attestation generation became the bottleneck.
Furthermore, MEV-boost involves resource-heavy workloads such as simulating transactions, and we want to be able to put a bunch of instances of the service behind a load balancer.
Many of the solutions we considered to get around the issue of needing to wait for attestation generation on every TLS session involved establishing trust in a particular CVM instance, so that attestation can be skipped the second time around. With a load balancer this would not work as clients have no control over which instance they are going to get and would need to establish trust in the whole fleet in order to guarantee that their subsequent sessions can be established quickly. The more instances, the harder this becomes.
We needed a redesign.
New Requirements for a protocol
To address these issues, we set out to design a new protocol that met the following requirements:
- CVM instances should boot and become operational fast and with minimal reliance on third parties. Needing to do ACME on a per-boot basis before an attested channel can be established is unacceptable.
- Attested channels should be fast to establish such that many concurrent channels can be established quickly. Needing to wait for attestation generation for every session is unacceptable.
- In the case of deployments with multiple service instances, individual CVM instances should not need to be publicly addressable such that they can be accessed via a load balancer. That is, a client cannot directly specify an instance it has previously connected to and established trust in. Rather, it should check at the point of establishing a connection whether the instance the load balancer has provided is trusted.
Finding a design which met these requirements while upholding security was not easy. TLS session binding doesn’t work because of the serial nature of attestation generation. And binding to a keypair associated with a CA-signed certificate was not possible due to not wanting to do ACME at boot. Wanting to support load-balanced, multi-instance deployments meant that we could not retrieve an attestation out-of-band in order to establish trust in a particular instance of a service before starting a TLS session, as there is no way to connect to a particular instance.
A nested-TLS design

What we went for is nested TLS, that is, a second TLS handshake sent as application data in an existing TLS session. Actual application data is then double-encrypted in the nested session.

The first TLS handshake forms the ‘outer’ session, and once that is established we begin a second handshake for the ‘inner’ session which is secured by the outer session.
The outer session uses a vanilla CA-signed certificate with no attestation. This serves to establish endorsement from the domain owner, but the TLS private key may persist outside of the trust domain in order to fulfill #1.
The inner session uses self-signed certificates, or certificates signed with a custom private CA. These certificates contain an attestation in an x509 extension which are bound to details of the certificate such as the public key and validity period. The TLS private key for the inner session is generated inside the trust domain and should not persist across reboots. Because the inner certificate does not need to be signed by an external CA, it can be rotated very frequently.
The outer session is optional. For some use-cases we might not need the additional guarantees provided by a CA, and the protocol is designed so that servers can offer both nested TLS and inner-session-only on different ports, allowing the client to choose.
We did have concerns about this design with respect to performance. We expected that TLS records from the inner session would overflow the maximum size of those from the outer session, causing potentially twice as many TLS records to need to be processed as with a single session.
The cost of TLS-in-TLS
In practice, our benchmarking showed this didn’t happen even at high throughput - the number of TLS records which actually go over the wire was almost exactly the same (disregarding the initial second handshake). So although there is a notable performance penalty, it’s better than we anticipated.
Additional Handshake
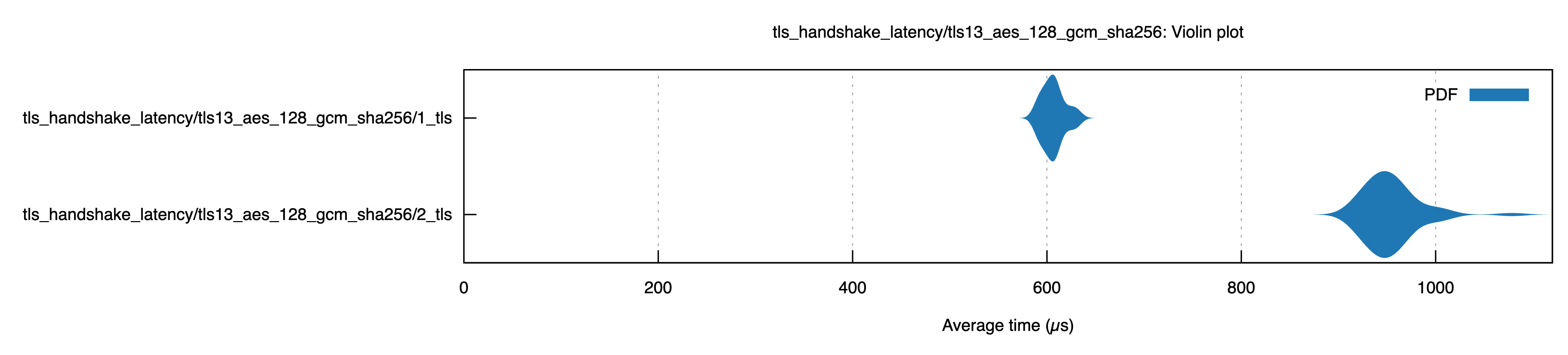
Initially we have an the extra network round trip for the second handshake - in our benchmarks this added ~0.35ms - 57% on top of the first 0.6ms handshake.
Overall Throughput
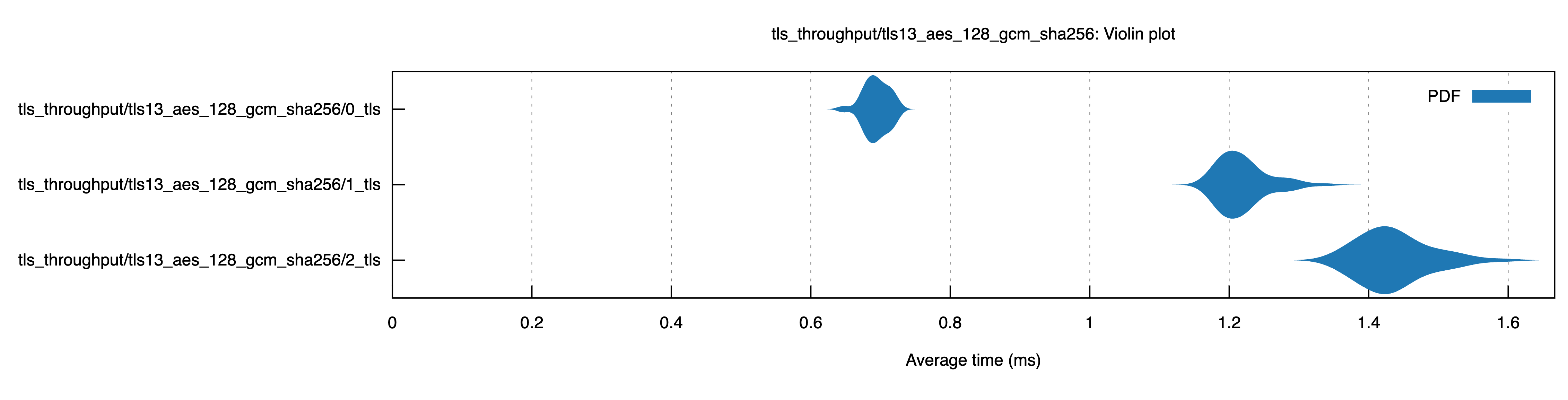
Overall, adding a nested TLS decreases throughput by 63.3MBps / 15% on a 512kb transfer. This sounds like a lot, but since that is a very small transfer, the impact of the initial second handshake is large. Things look better when we look at just the application traffic.
Latency per application byte transferred
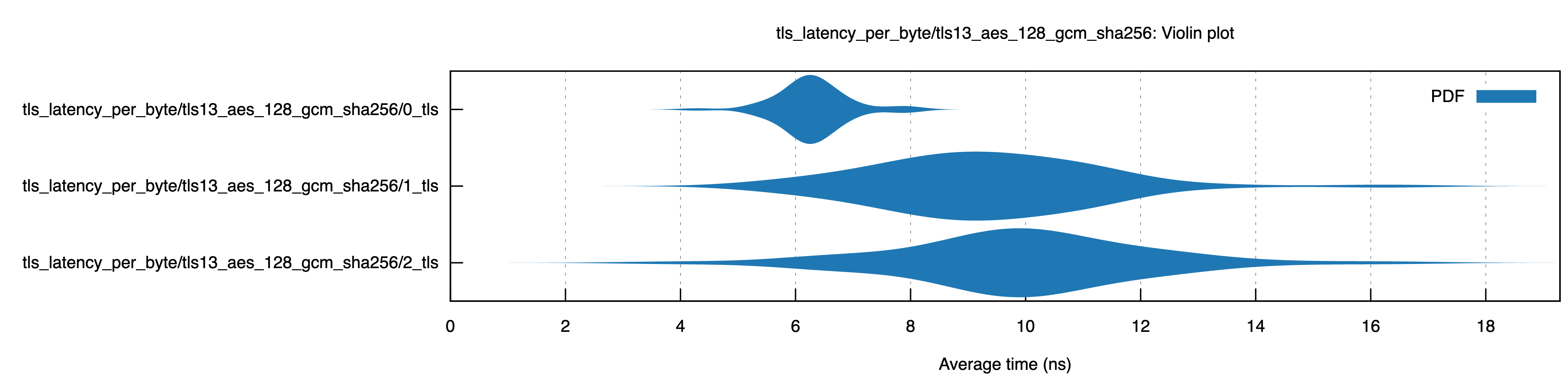
Every application-level TLS record has twice as much metadata and needs to be encrypted/decrypted a second time. This added around 0.6ns per byte (6%) in our benchmarks, which is small compared to the penalty of the initial TLS session (compare the top row which is plaintext).
We decided this performance cost was acceptable for the advantages this design provided for our use case.
Why this trade-off was worth it
This design means we can use a long-term certificate from LetsEncrypt which persists across CVM restarts, keeping CVM boot fast and no danger of being rate limited by the CA if we would need to frequently boot all instances. This is possible because the TLS private key for the outer session is controlled by the domain owner rather than being confined to the CVM, and so does not need to be generated on every boot. This means that the guarantees provided by the outer session are essentially the same as we get when using HTTPS for conventional (non-confidential) services.
The inner session provides the identity of this particular CVM instance boot, and the associated attested certificate can be renewed at a frequency of our choosing. There is no attestation generation in the hot path, and clients can cache attested certificates which they have already verified, making subsequent handshakes very fast.
So there are some notable advantages over our EKM-binding based protocol. But there are also disadvantages. In particular, there is no way to bind attestation to a verifier-provided nonce, and so no freshness guarantees. A short validity window for the attested certificate helps here, but verifiers still cannot know how old the provided attestation is. We would welcome feedback on this issue and are open to suggestions as to how to how to prove freshness without making the verifier wait.
In our Rustls-based implementation, all the logic could be provided in a custom certificate resolver and verifier making the API very neat and flexible when compared with our post-handshake attested-TLS protocol which required passing around an established TLS stream.
Conclusion
We aspired to coming up with a unified approach to attested TLS which we could use across all our CVM services. But ultimately, every project has different needs and no protocol is optimal for all. EKM-bound attestation remains attractive when connection establishment is infrequent. For throughput-critical systems requiring many concurrent connections and multiple service instances, this nested TLS design shines.