To Wait or To Probe: Arbitrage Competition on High-Throughput Blockchains
— Fei Wu (work during Flashbots internship), Burak Öz (@boz1)

tl;dr
MEV on high-throughput blockchains like Base is captured in two very different ways. Targeted searchers find the opportunity off-chain and send a route-committed transaction. Probabilistic searchers fire repeated attempts and let opportunity discovery happen during on-chain execution. The catch is that a failed attempt (i.e., a spam transaction) looks the same on-chain whether it came from a targeted bot that lost a race or a probabilistic bot whose probe found nothing.
In our new paper, we distinguish these search architectures using Base cyclic arbitrage data and a trace-level classifier, and show that they differ in execution behavior, attempt efficiency, and spam production. We study how protocol configuration changes, such as Flashblocks and fee floors, and opportunity shocks, such as token launches, shape the arbitrage competition and the viability of these architectures. Finally, we show that the resulting architecture viability and bot behavior shape chain-level outcomes, including priority-fee revenue and blockspace consumption.
We’ve witnessed that MEV quietly eats the scalability gains of high-throughput chains. On Base, a single successful arbitrage can sit behind something like 350 failed attempts and consume gas equivalent to several full Ethereum blocks. We ask the structural question underneath it: which kind of bot produces the spam, why, and what protocol features make each kind viable.
From Economic Strategy to Bot Implementation
On Ethereum L1, MEV is almost always extracted through targeted search: identify and simulate an opportunity off-chain, then submit a transaction already committed to a specific route. On high-throughput chains, fast blocks, low fees, and limited state visibility make a second architecture viable: submit many transactions that read live state and resolve opportunity discovery on-chain, only proceeding to execution when a profitable route is found. We call this probabilistic search.
At the implementation level, these two economic strategies show up as three distinct patterns, distinguished by where route discovery happens and what’s visible in the transaction trace:
- Off-chain discovery with direct execution — the cleanest targeted implementation. The route, venues, and input amount are embedded in calldata; the transaction goes straight to swaps with no pre-swap pool reads. Discovery happens entirely off-chain.
// Route is already encoded in calldata.
// No pre-swap state read: execution starts directly on the first pool.
// The later STATICCALLs are route-local checks on bot balances and venues already used in the route.
bot.execute(route)
route = [
pool 0xdbc6…30f1, // Uni-V3-style pool
pool 0x4bc4…c29d // Balancer-style pool via vault 0xba1333…ba9
]
── first swap ─────────────────────────────
swap 0.128 WETH → ~383.22 USDC
in pool 0xdbc6…30f1
// Pool sends USDC to the bot, then calls back for WETH repayment.
── callback: uniswapV3SwapCallback ────────
staticcall 0xdbc6…30f1.token0()
staticcall USDC.balanceOf(bot)
staticcall 0x4bc4…c29d.getVault()
→ vault 0xba1333…ba9
── second venue ───────────────────────────
swap ~383.22 USDC → 0.1280325 WETH
in pool 0x4bc4…c29d
via vault 0xba1333…ba9
── repay first swap ───────────────────────
transfer 0.128 WETH → pool 0xdbc6…30f1
── profit ─────────────────────────────────
sweep ~0.0000325 WETH → payout 0xd2be…bee4
- Broad on-chain discovery — the canonical probabilistic implementation. The transaction scans a wider set of pools than it ultimately executes on, reads state to find which subset is profitable, then executes. That strict superset relation — reads of venues never executed — is the trace-level signature of discovery-during-execution
// Broad on-chain discovery example.
// Root calldata is empty: the final route is not visibly pre-committed in calldata.
// Before any swap, the bot scans many candidate pools with STATICCALLs.
bot.execute()
── broad pre-swap scan ─────────────────────
staticcall 0x7d18…64c0.getReserves()
staticcall 0xb6b6…09be.slot0()
staticcall 0xb0f4…5eef.slot0()
staticcall 0xc6fb…b076.getReserves()
staticcall 0x940e…050f.getReserves()
...
// dozens of additional getReserves(), slot0(), balanceOf(), tick/quote reads
// across pools that are not all executed later
── route chosen after scan ─────────────────
call router/helper 0x4985…b2b
route selected:
pool 0x20cb…fd0
pool 0x7cf6…d10
pool 0xf702…d2d
── first executed pool ─────────────────────
swap in pool 0x20cb…fd0 // Uni-V3-style swap, selector 0x128acb08
── callback ────────────────────────────────
bot receives callback from 0x20cb…fd0
...
── second executed pool ──────────────────
swap in pool 0x7cf6…d10 // V2-style swap, selector 0x022c0d9f
...
── third executed pool ─────────────────
swap in pool 0xf702…d2d // Uni-V3-style swap, selector 0x128acb08
repay / settle callback obligations
── profit / sweep ──────────────────────────
WETH.balanceOf(bot)
WETH.withdraw(...)
send ETH profit → 0x7813…7c2a
- Route-confined on-chain evaluation — the transaction carries a pre-selected route in calldata but reads live state from those same venues before committing, as a profitability check. This is economically closer to targeted search, but it’s intrinsically ambiguous from traces alone: confined reads could be a targeted searcher re-validating a known route, or a narrow probabilistic searcher discovering one over a venue set that happens to coincide with what it executes.
// Route-confined on-chain evaluation example.
// The route is encoded in calldata.
// Its pre-swap STATICCALLs are confined to the two venues it later executes on.
bot.execute()
route = [pool 0x4235…e8b, pool 0x381e…c92]
── route-local pre-swap checks ─────────────
staticcall 0x4235…e8b.slot0()
staticcall 0x4235…e8b.liquidity / pool state
staticcall 0x4235…e8b.fee / config
staticcall 0x381e…c92.getReserves()
── first executed venue ────────────────────
swap in pool 0x4235…e8b // Uni-V3-style swap, selector 0x128acb08
sends token 0xfca9…6bf7 → pool 0x381e…c92
then calls back to the bot for WETH repayment
── callback: uniswapV3SwapCallback ─────────
staticcall 0x381e…c92.getReserves()
── second executed venue ───────────────────
swap in pool 0x381e…c92 // V2-style swap, selector 0x022c0d9f
receives ~0.00043415 WETH
── repay first swap ────────────────────────
transfer ~0.00043229 WETH → pool 0x4235…e8b
── profit ──────────────────────────────────
keep residual ~0.00000186 WETH
All three can produce failed attempts (spam), but for different reasons: a route-committed transaction may find that the targeted opportunity has disappeared, while a probabilistic search transaction may fail to find any profitable route during execution. We use failed attempts as the umbrella term and split it: probes terminate after state reads without executing swaps; reverts revert during execution.
| Pattern | Strategy | Route Discovery | Fail Condition |
|---|---|---|---|
| Off-chain discovery | Targeted search | Off-chain | Opportunity disappears |
| On-chain discovery | Probabilistic search | On-chain | No opportunity exists |
| On-chain evaluation | Targeted / Probabilistic search | Off-chain / On-chain | Opportunity disappears / No opportunity exists |
Prior works have documented spam MEV volume on Base, Optimism and Arbitrum, characterized probabilistic search timing, and modeled equilibrium spam volume. But the measurement counts spam without formally separating the architectures that produce it, and these models typically study a single (the probabilistic) search architecture.
Data and Methodology
We use Base from June 1, 2025 to February 28, 2026, a window spanning its major configuration changes. We collect 21,374,434 successful arbitrages across 4,365 bot addresses, and their corresponding failed attempts — 985,559,360 spam transactions (35.7M reverts, 949.9M probes).
To identify bot architecture, we sample up to 50 successful arbitrages per bot-week (359,752 sampled transactions, 4,365 bots, 39 weeks) and run a trace-level classifier on debug_traceTransaction call traces. It decomposes each trace into route-attempt subtrees, compares pre-execution venue reads against the executed-venue set, and assigns one of three labels according to the implementation introduced above — OFFCHAIN_DIRECT, ONCHAIN_EVAL, ONCHAIN_BROAD_SCAN.
We aggregate these transaction labels weekly into bot labels:
- a bot-week is on-chain discovery if it has any
ONCHAIN_BROAD_SCANtransaction; - a bot-week is off-chain discovery if it has any
OFFCHAIN_DIRECTtransaction; - a bot-week is on-chain evaluation only if all sampled transactions are
ONCHAIN_EVAL.
The Character of the Three Architectures
| Bot label | Bots | Arbs | Spam | Reverts | Probes | Success rate | Median / P95 avg. spam tx gas | Avg. cost per success |
|---|---|---|---|---|---|---|---|---|
| Off-chain discovery | 1,634 | 7.67M | 23.63M | 16.86M | 6.78M | 42.51% | 352K / 1.02M | 0.000095 ETH |
| On-chain evaluation | 798 | 8.83M | 27.63M | 12.51M | 15.12M | 18.49% | 64.8K / 371K | 0.000045 ETH |
| On-chain discovery | 2,049 | 4.87M | 934.30M | 6.29M | 928.01M | 4.58% | 277K / 1.39M | 0.000253 ETH |
Table — Bot activity by weekly architecture label. Success rate is bot-level average, calculated as total success divided by total attempts. Categories aren’t mutually exclusive because bot labels can vary across weeks.
We first show that the three bot architectures differ in their observable behavior, both in successful arbitrages and in spam.
Off-chain discovery bots produce the least spam and the highest success rate (42.51%), and their spam is mostly reverts — direct execution with pre-committed routes that run most of the swap logic before failing, which is why their per-spam gas is high (median 352K) but their cost per success stays moderate, since few failures accompany each success.
On-chain evaluation bots sit in the middle: lightweight, confined checks, the cheapest spam (median 64.8K gas) and lowest cost per success (0.000045 ETH).
On-chain discovery bots generate 934.30M spam transactions — almost all probes — at a 4.58% success rate. The P95 (1.39M) average spam gas reflects a tail of very wide route searches. The compound effect of heavy route search and low success rate is the highest cost per success (0.000253 ETH).
| Bot label | Median calldata length | Avg / Median venue commitment | Median pre-reads |
|---|---|---|---|
| Off-chain discovery | 516 | 0.607 / 0.971 | 0 |
| On-chain evaluation | 150 | 0.535 / 0.886 | 3 |
| On-chain discovery | 91 | 0.184 / 0.000 | 40 |
Table — Bot architecture and trace-level metrics from sampled arbitrages. Venue commitment is defined as the fraction of executed venue addresses embedded in calldata.
The trace-level fingerprints in their successful arbitrages further support that they’re economically distinct architectures.
Off-chain discovery: longest calldata, high venue commitment, zero median pre-execution reads, consistent with pre-committed routes carried in the transaction itself and direct execution behavior.
On-chain discovery: short calldata, zero median venue commitment, and 40 median pre-reads, indicating that the route is resolved during execution through dense state reads across many venues.
On-chain evaluation: sits between the two, with modest pre-reads against the confined set of venues they subsequently execute on.
Timeseries Overview
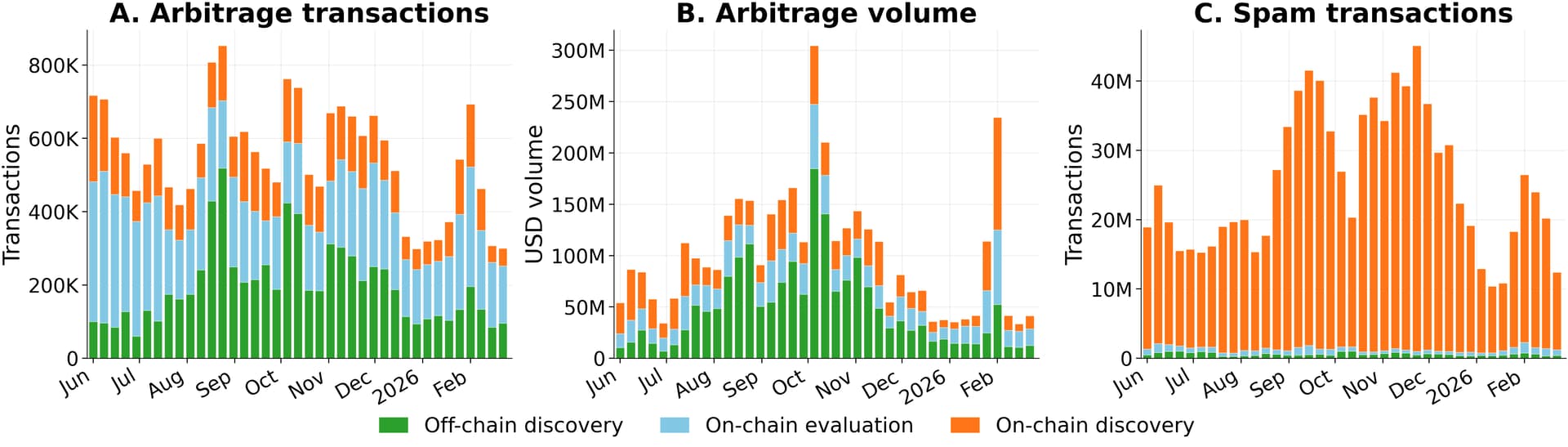
Figure - Weekly successful arbitrage transaction count, USD volume, and spam transaction count by each bot architecture label.
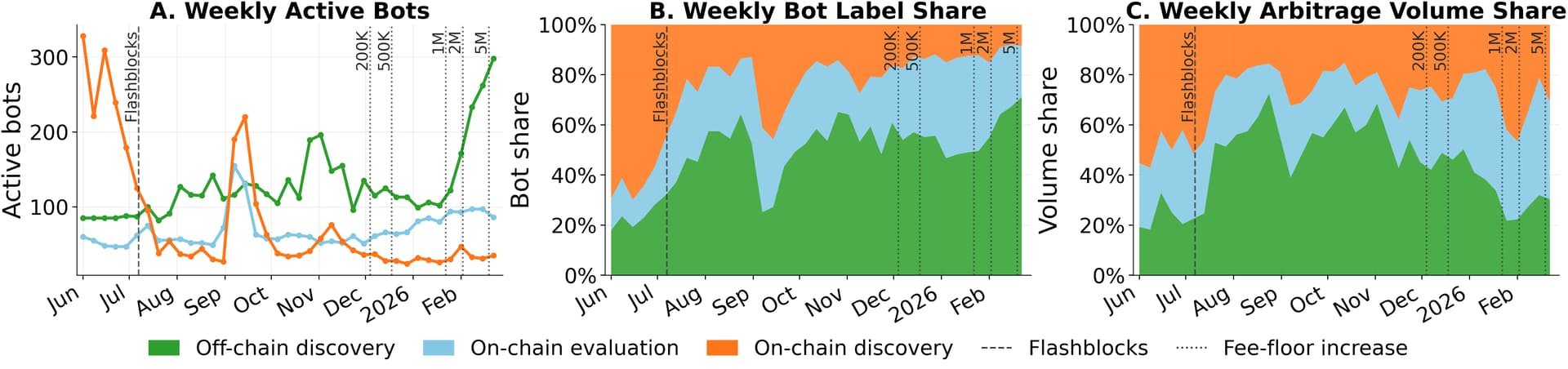
Figure - Weekly number of active bots per label, weekly active bot label share, and weekly volume share per bot label. Vertical lines mark configuration changes of Flashblocks and fee floors.
Across the full sample, on-chain discovery bots account for 22.8% of successful arbitrages and 28% of volume — yet ~95% of total spam. In most weeks, just 30–50 active on-chain discovery bots generate roughly 20M spam transactions a week.
The time series highlight three episodes — Flashblocks (July 7, 2025), the September on-chain discovery surge, and the minimum-base-fee escalation (from December 4, 2025).
Flashblocks
Flashblocks, activated on July 7, introduced 200ms pre-confirmation sub-blocks inside Base’s 2-second cycle. Each Flashblock has an incrementally increasing gas budget, until the final Flashblock within a block has access to the full block gas limit.
Under Flashblocks, early sub-blocks have limited space, so heavy on-chain discovery transactions that conduct broad venue scanning are more likely to be displaced than the lean route-committed transactions that off-chain discovery bots use to target the same opportunity.
As a result, we see a population and volume shift. In a four-week symmetric window around Flashblocks activation, on-chain discovery’s share of active bots dropped from 63.1% to 25.1%, and its volume share roughly halved.
| Cohort | Bots | Median calldata length | Average venue commitment | Median pre-reads | Median arbitrage tx gas | Median of avg. spam tx gas |
|---|---|---|---|---|---|---|
| Selected out (pre only) | 741 | 36 | 0.044 | 57 | 855K | 671K |
| Entrants (post only) | 120 | 244 | 0.258 | 46 | 630K | 272K |
| Survivors (pre → post) | 37 | 163 → 302 | 0.345 → 0.340 | 39 → 12 | 662K → 437K | 226K → 103K |
Table - On-chain discovery cohort composition and architecture metrics within the four-week pre- and post-Flashblock window.
The extensive margin is selection. The 741 selected-out on-chain discovery bots are the heaviest scanners (36-byte median calldata, 57 median pre-reads); entrants and survivors are markedly leaner. We also observe an intensive-margin adaptation within the survivors: they become even leaner after Flashblocks.
But here’s the twist: aggregate spam stays nearly flat (68.43M in the 4-week pre-window → 70.50M in the 4-week post-window) because spam per active bot rises from 72.49K to 314.71K. Finer ordering changes who probes and narrows their search, but doesn’t price attempt frequency. Instead of scanning broader within each transaction, they switch to scanning more frequently. Meanwhile off-chain discovery got more efficient (success 35.8% → 43.6%), consistent with shorter intervals that release state information more frequently and reduce stale-state risk.
The September Surge
In an otherwise stable post-Flashblocks regime without a broad, sustained market-wide expansion, on-chain discovery bots spiked to 220 in the week of September 14, then collapsed back to ~35 by early October.
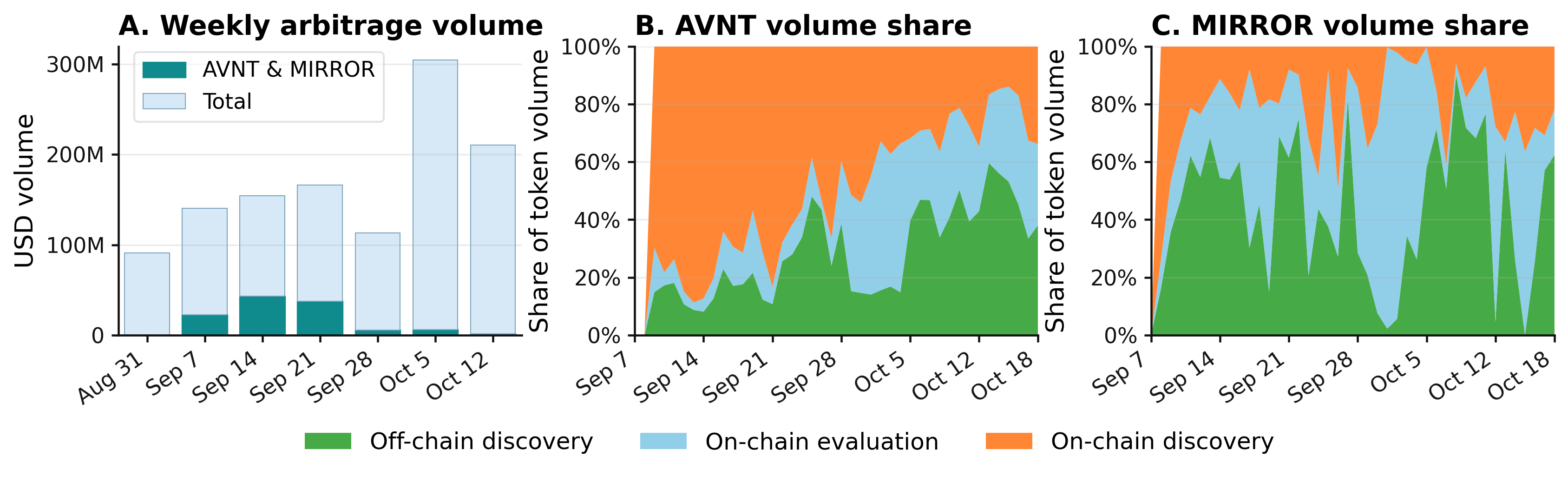
Figure - AVNT and MIRROR arbitrage activity around their launch.
The revival is around two token launches: MIRROR on Sept 8 and AVNT on Sept 9. Many on-chain discovery bots enter the market in September and retreat as AVNT/MIRROR volume fades in October. Between Sept 7 and Oct 4, 504 unique on-chain discovery bots were active, 464 of them (92.1%) transient — first and last seen within this period. AVNT/MIRROR were 19.3% of all arbitrages and 42.8% of on-chain discovery arbitrages, and the concentration was strongest among the short-lived triers. Afterwards, on-chain discovery’s share of AVNT/MIRROR volume falls quickly, while the other two architectures absorb the bulk of the flow.
We interpret this as on-chain discovery being temporarily more competitive when new token routes appear and are not yet indexed by off-chain bots — not because these bots discover pools faster, but because fresh launches bring dispersed retail flow, uncertain venue quality, and many short-lived route candidates, which makes on-chain probabilistic searching attractive. As routes become easier to monitor and parameterize off-chain, the flow shifts toward on-chain evaluation and off-chain discovery, and most short-lived entrants exit.
The episode generated a temporary spam shock of 147M transactions, 72% of it from the transient cohort that promptly vanished. Probing isn’t dead; it’s contingent.
Note: We treat this as illustrative rather than a clean event study, since it overlaps the per-transaction gas-limit change on Sept 17.
Fee Floor Escalation
To mitigate the spam externality, Base introduced a minimum base fee and ramped it in five steps — 200K, 500K, 1M, 2M, and 5M WEI between Dec 4, 2025 and Feb 17, 2026.
A higher fee floor raises the cost of every attempt, so it bites hardest on the architecture with the highest fee exposure. On-chain discovery, with many attempts per success and a low success rate, is exactly that.
The population shift matches. Across the ramp, on-chain discovery’s share of active bots falls from 22.0% to 8.4%, while off-chain discovery rises to 71.1%. As with Flashblocks, this is selection and replacement, while the surviving on-chain discovery bots still capture non-trivial flow, so a smaller, high-productivity core remains.
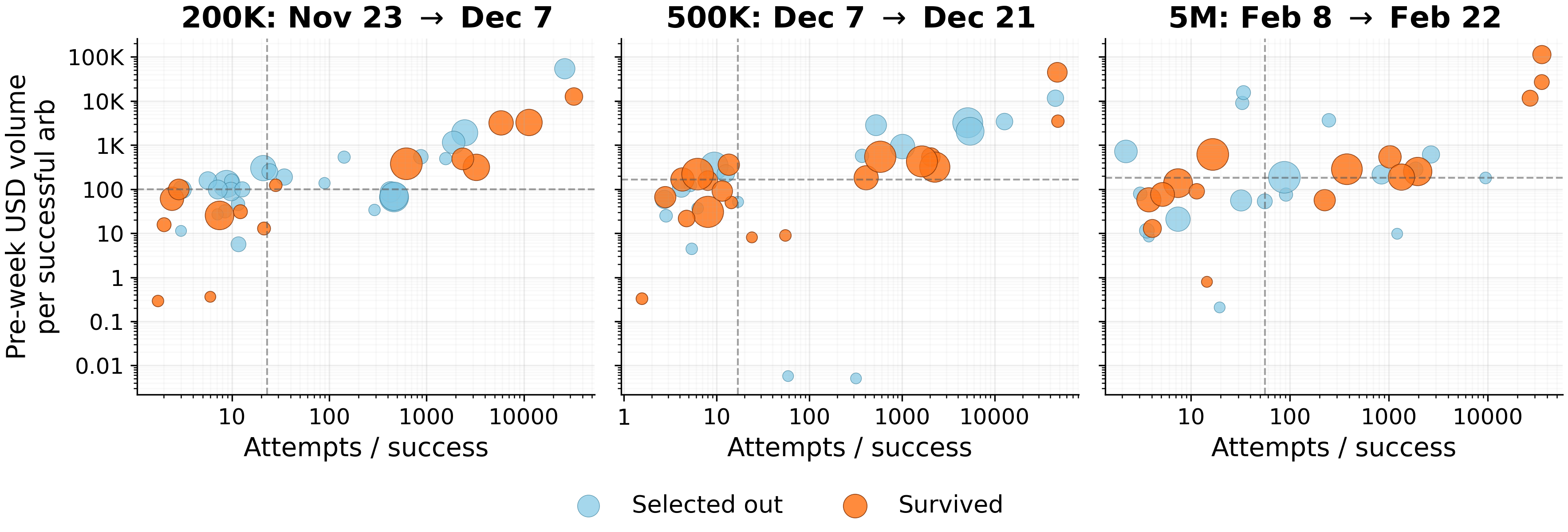
Figure - On-chain discovery bots active before the fee steps of 200K, 500K and 5M WEI, plotted by attempts per successful arbitrage and USD volume per successful arbitrage. Orange = survived the step, blue = selected out; marker size scales with volume. We use volume as a proxy for value of captured opportunity.
The selection is two-dimensional. Neither attempt intensity (i.e., how frequently bots submit attempts) nor value per success alone predicts survival. Bots with high volume per success and few attempts survive comfortably; bots with low volume per success and many attempts are disproportionately selected out; and bots that probe heavily survive only when their opportunities are valuable enough to cover the cost.
The fee floor does not simply eliminate the highest-attempt bots. It raises the hurdle rate for probing: high-attempt strategies survive only when backed by enough opportunity value. Consistent with this, surviving bots’ USD volume per attempt rises across the clean steps (0.36 → 0.87 at 200K, 0.46 → 1.31 at 5M).
This is a different knob from Flashblocks. Unlike finer ordering, the fee ramp doesn’t push survivors toward leaner, less scan-intensive transactions at the trace level: broad scanning stays profitable when the opportunities are rich enough. What dies is low-yield probing, not probabilistic search itself.
Note: Some fee steps are not clean. The 500K step coincides with a broad market contraction in late December 2025. The 1M and 2M steps overlap with an opportunity-driven on-chain discovery episode similar to the September surge. See the paper for details.
Chain-Level Consequences
Finally, we ask whether these architecture responses to protocol changes actually improved outcomes for the chain, on two fronts: priority-fee revenue and blockspace consumption.
Priority fees
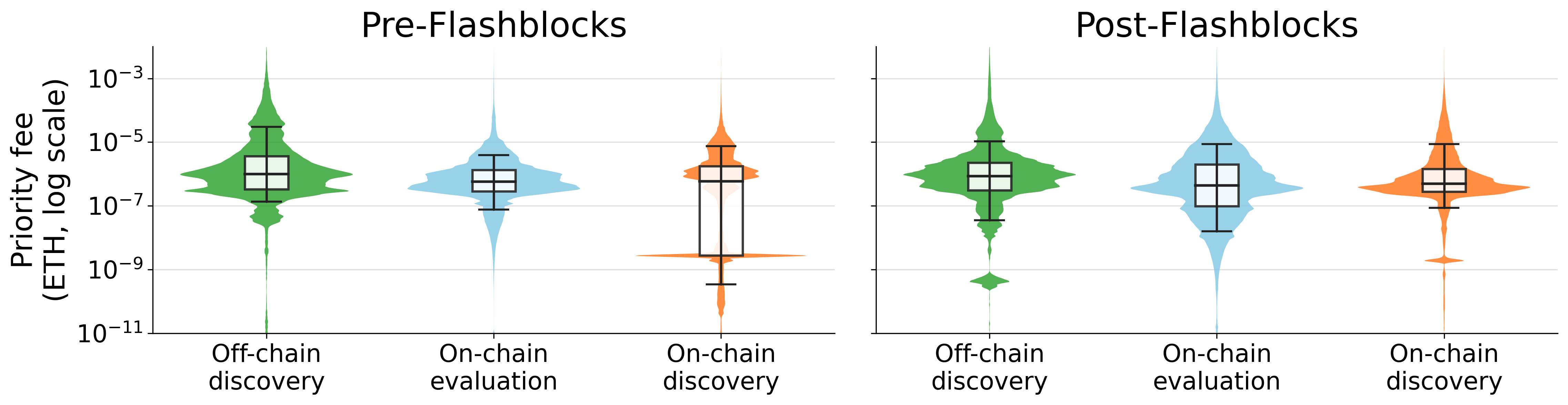
Figure - Priority-fee distributions for successful arbitrages by architecture before and after Flashblocks (3.04M arbitrages pre, 17.40M arbitrages post).
Off-chain discovery pays the highest median priority fee per successful arbitrage (8.66×10⁻⁷ ETH, vs 4.72×10⁻⁷ for on-chain evaluation and 5.02×10⁻⁷ for on-chain discovery), consistent with off-chain discovery targeting more valuable or more time-sensitive opportunities, where route simulation and input optimization support higher willingness to pay for inclusion.
After Flashblocks, on-chain discovery’s pronounced low-fee mass shrinks and its distribution moves toward the others. This pattern is consistent with Flashblocks selecting out the broadest low-revenue scanners and leaving a smaller population whose attempts are more targeted.
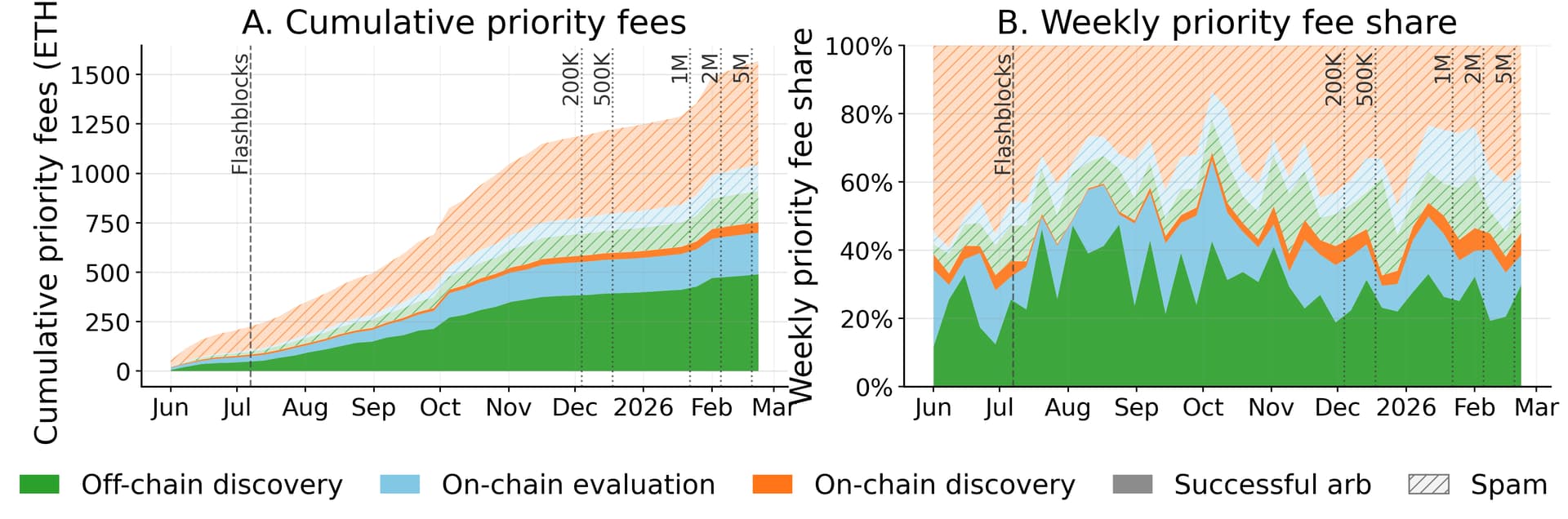
Figure - Cumulative and weekly share of priority-fee payments by bot architecture and transaction outcome. Colors denote bot architecture; solid areas denote successful arbitrages and hatched areas denote spam.
Consequently, spam’s share of weekly priority fees gradually falls from over 60% pre-Flashblocks to ~40–45% after. Flashblocks changes not only which bots remain active, but also how surviving on-chain discovery bots bid for inclusion.
The fee-ramp period is harder to interpret because policy changes overlap with low-activity periods and a mid-ramp opportunity shock. Even so, the successful-arbitrage share rises following the 500K step, despite volume contraction, consistent with selection against low-value, high-attempt-intensity bots.
The priority-fee improvent illustrates a higher-quality arbitrage market: spam still pays fees, but after Flashblocks, surviving on-chain discovery bots bids higher for inclusion, and a larger share of arbitrage-related priority fees comes from successful captures.
Blockspace Consumption
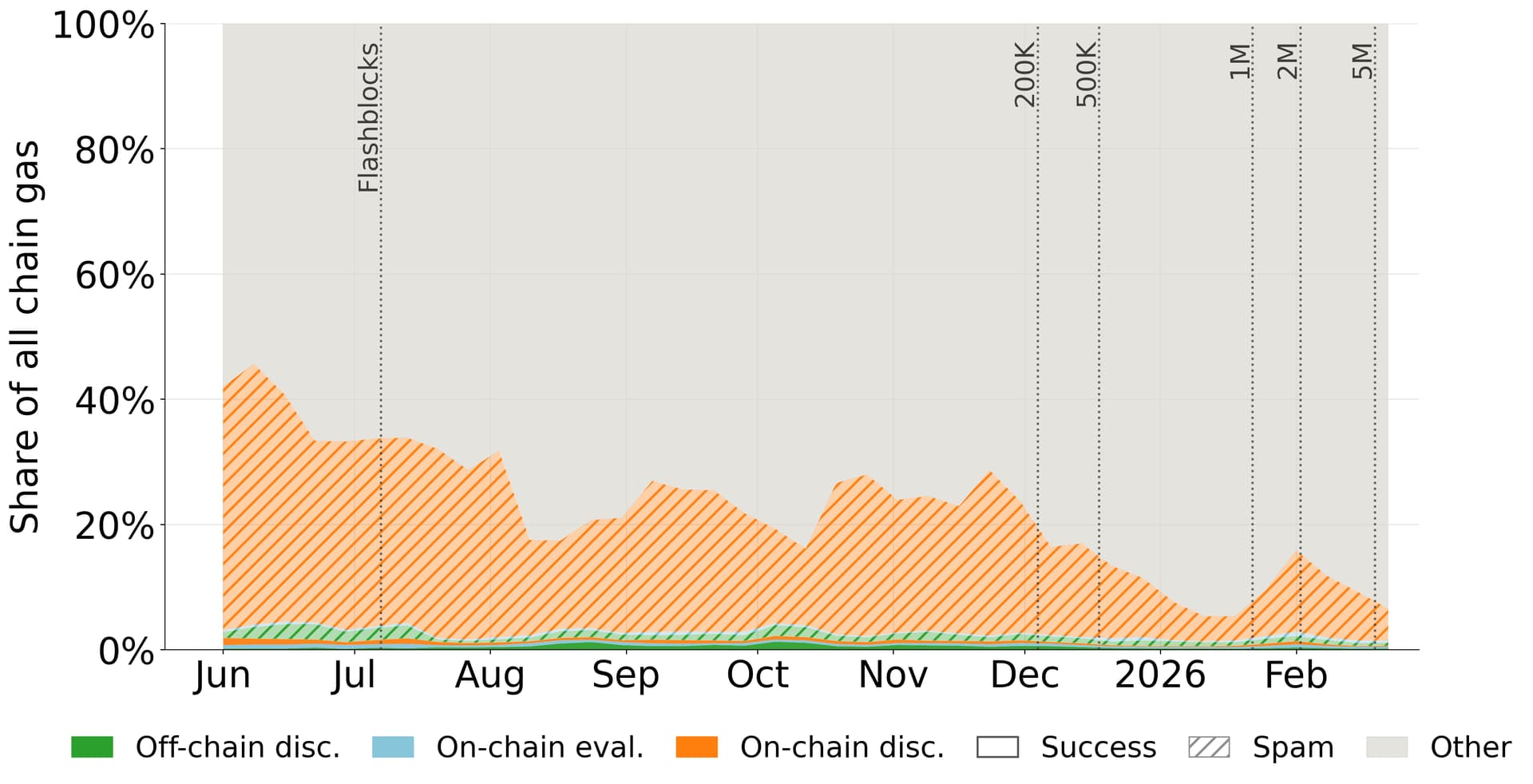
Figure - Arbitrage-related weekly gas usage share.
Across the full sample, successful arbitrages across all three architectures consume just 1.31% of total Base gas. The burden is almost entirely spam — and almost entirely one architecture: on-chain discovery spam alone is 19.59% of all Base gas, out of 20.92% total spam gas.
After Flashblocks, the spam gas share falls from roughly a third-to-half of weekly gas down to ~15% once a few extreme bots exit or downscale. Even during the September surge episode and afterwards, where spam transaction count is nearly double the pre-Flashblocks period, spam gas consumption does not return to the pre-Flashblocks level.
The spam gas consumption declines further through the fee ramp, aside from temporary opportunity shocks. Through selecting against broad, low-yield probing, Flashblocks and the fee ramp improve the efficiency of Base blockspace usage.
Did Base Succeed?
Arbitrage competition on high-throughput chains is not just a contest over who extracts MEV, but over which search architecture the protocol makes viable. So were Base’s configuration changes a success? They clearly did not eliminate spam ---- failed attempts persist throughout our sample. A more meaningful question could be: is the new competitive equilibrium preferable for the network? We think it is, with caveats.
The clearest win is improved efficiency: arbitrage bots now consume less blockspace. Flashblocks increased successful activity by targeted searchers, pruned the high-footprint on-chain scanners, and increased probabilistic searchers’ bid for inclusion. Higher fee floors then raised the hurdle rate of repeated probing by making each attempt more expensive.
But the equilibrium adapts rather than collapses. For example, after Flashblocks, probabilistic searchers responded to more competitive targeted searchers by sending more attempts, despite each doing less venue scanning. Opportunity shocks can revive probabilistic search outright — the September token launches did, and so did a Janurary episode even under a higher fee floor.
The form of competition have changed and efficiency improves on most days, yet arbitrage attempts still fail, especially under high activity times. Hence, Base’s configuration updates can be seen as succesful on average, without terminally ending inefficient blockspace usage.
Wat else can we do?
While the protocol can further increase the fee floor or change the way of charging for blockspace usage to make every arbitrage attempt more expensive, failed attempts from different architectures call for different mitigation tools.
For route-committed reverting attempts from targeted searchers, revert protection is a natural tool. Such protection exists on Ethereum Layer-1 through transaction bundling and block building mechanisms, and on Unichain through Rollup-Boost. It has been shown to improve market and blockspace efficiency. However, it does not eliminate early-terminating targeted profitability checks or probabilistic probe spam.
Reducing probe-like spam requires mechanisms that improve information availability or reduce the incentive to use transactions as information-gathering devices. One approach is to make fresh state information available more frequently, so that searchers can simulate opportunities off-chain with less stale-state risk. Another approach is to allocate backrunning opportunities more explicitly. Examples include richer real-time information channels, protocol-run backrunning, and privacy-preserving backrunning auctions like MEV-Share. On high-throughput chains, these mechanisms face a tight tradeoff between information freshness, auction efficiency, latency, and user protection.
Future Research
Our study shows how ordering granularity, transaction costs, and opportunity shocks on Base shapes the relative competitiveness of arbitrage bot architectures and the corresponding chain-level outcomes. Future work can focus on expanding the scope, covering other forms of MEV with similar competitive dynamics on different blockchains, and different priority-access mechanisms. We detail some of such research directions.
-
Other MEV forms and other blockchains. Does the targeted/probabilistic split generalize? Liquidations can be targeted (waiting on oracle updates against known positions) or probabilistic (repeatedly probing for liquidatable ones), and cross-domain arbitrage may vary similarly. Future work could test whether these MEV forms exhibit analogous search architectures, how they respond to protocol changes, and what externalities they impose.
Across chains, Ethereum and Arbitrum likely favor targeted search (costly failed attempts and mempool visibility on Ethereum; fast block time reducing stale-state risk on Arbitrum), Optimism is the closest Base comparison via the OP Stack. Solana or Monad offers a high-throughput contrast with a different environment. -
Priority-access mechanisms. How do mechanisms that sell priority, such as Arbitrum’s Timeboost, reshape the competition? Timeboost may favor targeted searchers that can forecast and monetize latency advantages, while leaving probabilistic search viable only for operators with enough opportunity flow to justify the cost. Existing evidence that express-lane access is concentrated and that roughly 22% of time-boosted transactions revert suggests that priority access alone does not eliminate spam. Optimism’s recent experiment with stake-based priority ordering provides another setting of priority-access mechanism.
References
- [1] To Wait or To Probe: Arbitrage Competition on High-Throughput Blockchains. Fei Wu, Burak Öz.
- [2] MEV and the Limits of Scaling. Robert Miller.
- [3] Optimistic MEV in Ethereum Layer 2s: Why Blockspace Is Always in Demand. Ozan Solmaz et al.
- [4] Blockspace Under Pressure: An Analysis of Spam MEV on High-Throughput Blockchains. Wenhao Wang et al.
- [5] Timing Games: Probabilistic backrunning and spam. Bruno Mazorra, Christoph Schlegel, Akaki Mamageishvili.
- [6] Dealing with spam caused by on-chain searching. Quintus Kilbourn.