I found myself going back and forth in a peculiar loop recently, and gained some insights that I thought might be useful for (EL) client developers who are looking to test their nodes.
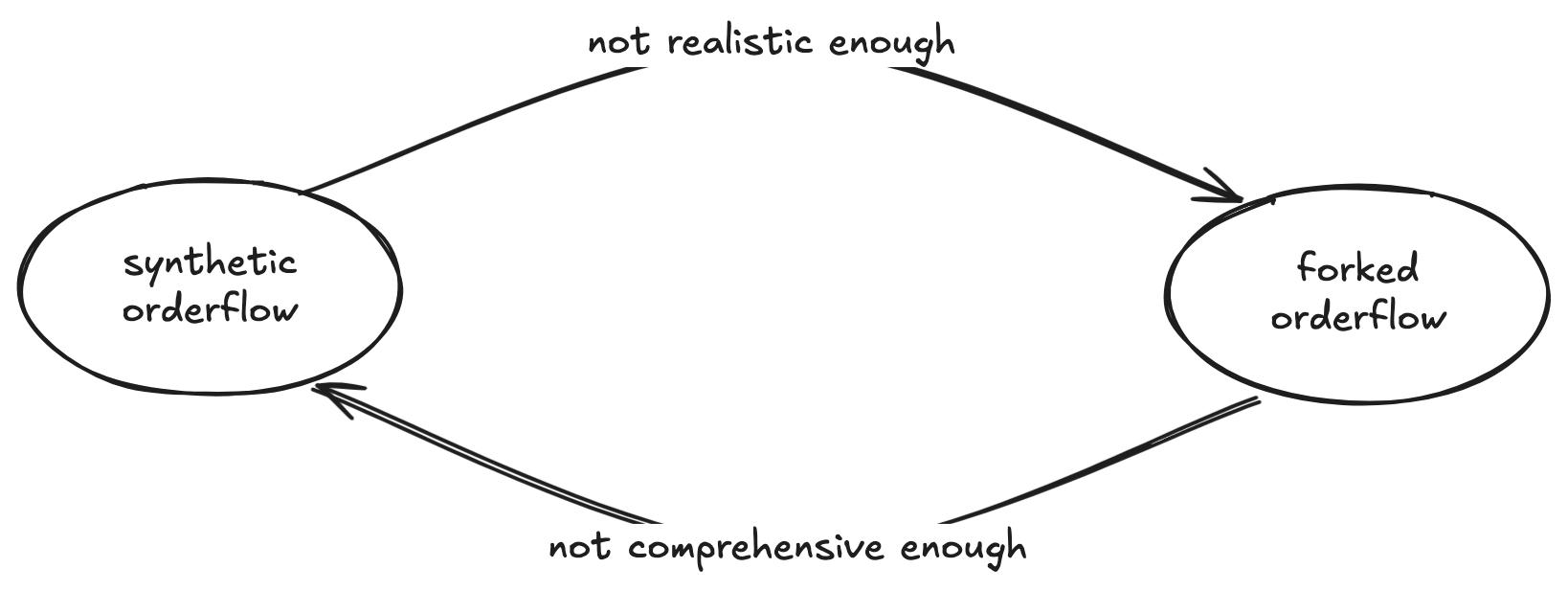
When testing transaction performance in an execution node (specifically, running/simulating transactions), you essentially have two options: synthetic orderflow (transactions you create), and forked orderflow (transactions that have already been included on a live chain).
With synthetic orderflow, you will always be able to create a transaction that meets a narrowly-defined set of needs by writing/deploying your own smart contract(s) and executing transactions that call its functions. However, as these transactions are necessarily narrowly-scoped tests, they don’t necessarily provide a comprehensive look at how the node will behave in production.
On the flip side, forked orderflow executes real-world transactions on your node, which is naturally the most realistic measure of performance. The downside is that you have no flexibility in your test definitions; you’re stuck with the transactions/blocks that you can find in the wild. This makes it much harder to find and test edge cases.
Depending on your needs, you may find that one or the other satisfies your testing requirements. But if you’re developing new EL clients, you’ll likely need to use both:
- synthetic orderflow to run uncommon/specific scenarios and find edge cases
- forked orderflow to check performance on real-world data; a simple sanity check
Contender, as it exists at the time of writing, falls in the synthetic orderflow category. Contender scenario definitions make it very easy to write a new test and run it against your node. In Contender, we use eth_sendRawTransaction to send transactions to the node, which makes contender universally applicable to nodes that implement Ethereum’s JSON-RPC spec.
One tool that falls in the forked orderflow category is gas-benchmarks. This is a tool by Nethermind which uses engine_ calls to execute pre-recorded full blocks on the node. This lets the user run a large amount of transactions quickly, and with minimal setup cost. One downside to this approach is that the engine_ method you call may not be supported on the target node; there are several versions of the engine API, so it will be more tedious to support all target nodes when implementing this approach.
Ultimately, if we want the most comprehensive generalized testing suite for EVM-based execution nodes, we’ll need to arrive at a combination of both synthetic-, and forked-orderflow testing methods. Each serve a specific and uniquely valuable purpose, and I don’t see a way to exclude one or the other.