Extending Sandboxes to New MEV Types
After piloting our TEE-based sandbox solution for bottom-of-block MEV earlier this year, we’re looking to extend searcher sandboxes to new types of MEV. Our existing searcher sandbox works for bottom-of-block MEV because it deals with aggregated information and leftover block space. Searchers receive merged state diffs, meaning their trades execute strictly after user transactions. As a result, they don’t compete with user trades. However, many applications we want to approach next involve MEV that is based on an individual transaction rather than aggregate state diffs. Unlike our current solution, these applications require searchers to insert their transactions directly behind user transactions, rather than at the end of the block. However, this creates a critical issue: when a searcher has access to multiple individual transactions within the same block, they can use their response to one transaction as an attack on another transaction, effectively creating sandwich attacks. The solution we’re exploring addresses this information accumulation problem through “ephemeral” sandboxes—execution environments that can be quickly reset to prevent searchers from building up sensitive knowledge over time.
The Problem
MEV-share provides a clear example of this challenge. Currently, our MEV-share system avoids TEE technology entirely, instead preserving user safety by limiting the information provided to searchers. Searchers receive limited information for each transaction. For example, the tradable token pair (like USDT/WETH) and the specific DEX address where the trade will occur, collectively known as the “pool.” This forces searchers to submit large batches of transactions covering various amounts and directions. Unfortunately, this method lacks precision, and building algorithms tailored to such a restrictive system has a high adaption cost.
At first glance, extending our TEE sandbox approach to give searchers access to individual transactions seems like a natural solution. However, this creates a sandwich attack vulnerability. Here’s how the attack works: when a searcher simulates a transaction, they can estimate its rough position within the block. Armed with this knowledge, they can identify a potentially profitable victim transaction to sandwich. They then wait to receive another transaction that will likely execute earlier in the block. Once they find such a transaction, they can submit a “backrun” to that earlier transaction, which effectively becomes the front-end of their sandwich attack, while simultaneously submitting their own transaction as the back-end to complete the sandwich around the original victim.
We’ve explored several workarounds that limit searchers’ transaction capabilities—such as preventing multiple transactions for the same pool within a block or capping their buy/sell prices. While these approaches reduce the sandwich attack risk, they also severely constrain searchers’ ability to capture legitimate MEV opportunities. Rather than imposing restrictions on searcher behavior, an ideal solution would address the root cause: preventing information accumulation.
Ephemeral Sandboxes
To address this issue, we are currently exploring sandboxes that can be reset between transactions. In this system, searchers would set up their container environment once with whatever tools and algorithms they need. Then, for each new transaction, we quickly spin up a fresh instance of that environment to run their code. The searcher gets full computational flexibility, but can’t accumulate information across transactions, eliminating the sandwich attack risk entirely.
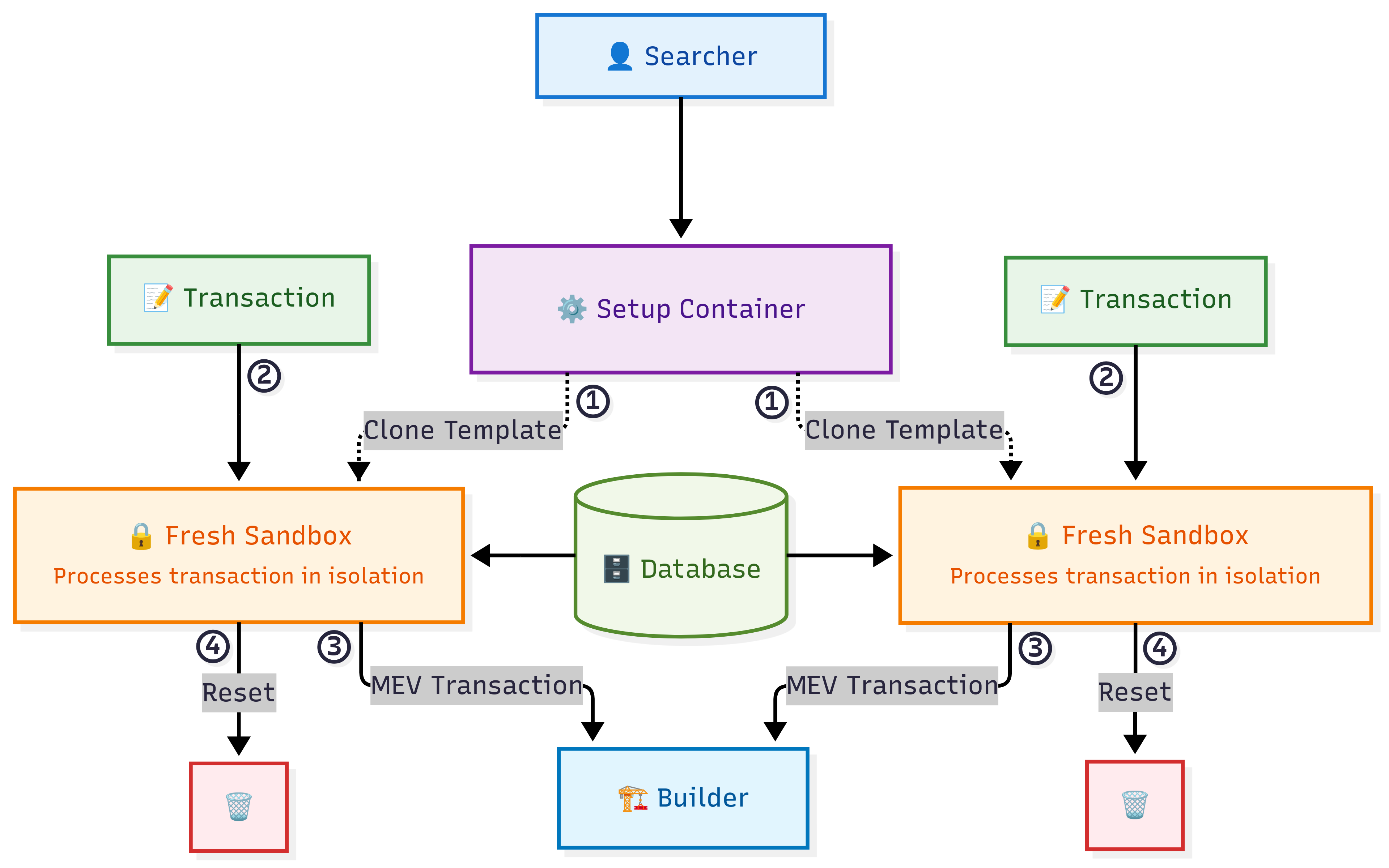
This ephemeral sandbox infrastructure represents an important new building block for democratizing access across markets that currently favor participants with privileged resources or relationships. TEE-based sandboxes enable everyone to trust a system without requiring legal contracts, reputation systems, or established relationships. Today, competitive advantages and market unfairness often stem from private arrangements with data providers, superior computing infrastructure, or established trust networks that exclude smaller participants. Whether in decentralized protocol auctions, high-frequency trading, or other competitive environments, success frequently depends more on access to exclusive information streams or computational resources than on algorithmic innovation itself.
Our existing bottom-of-block sandbox already demonstrates this trustless approach, but it’s designed around aggregated state diffs and only works for that specific MEV type. Most other MEV types need a fundamentally different approach. This extension would bring the same trustless guarantees to the much larger class of problems where individual data points arrive sequentially and prior knowledge can be weaponized. In these environments, early access to individual transactions or data points allows sophisticated actors to exploit previous data providers and subsequent searchers. By building memory reset capabilities on top of our proven TEE infrastructure, we can extend trustless participation to this broader spectrum of scenarios, transforming markets that have long been dominated by those with privileged access into genuinely merit-based competitions where all parties can participate confidently without legal agreements or reputation requirements.
Performance Tradeoffs
Building this infrastructure requires addressing three independent tradeoffs: optimizing sandbox performance while preserving flexibility, increasing parallelization without excessive resource costs, and safely reusing containers without constraining MEV possibilities.
The first challenge centers on balancing system performance requirements with searcher preferences. To illustrate this tension, consider a highly constrained approach where searchers submit code snippets through a simple interface with predetermined function signatures and limited programming language and library support. Such an environment could achieve the millisecond-level performance our most demanding use cases require, since every aspect of execution could be optimized for speed. However, searchers strongly prefer SSH access to a full Linux environment where they can install dependencies, run multi-process algorithms, and iterate on their strategies. This flexibility is particularly important because searchers lose access to traditional debugging methods when processing live transaction data, making it harder to iterate and develop code in restricted environments.
Standard approaches to restarting Docker or Podman containers operate on timescales that are too slow for our requirements by a factor of about 50. Whereas standard container software typically takes around half a second or longer, we’re hoping to achieve boot times of around 10ms. Some extreme use cases could even require hundreds of transactions per second of throughput. Other approaches can help address this challenge, though they’re less scalable than direct performance improvements.
One way we can increase throughput without decreasing container boot time is by keeping a pool of standby containers. However, each additional container consumes system resources. This is particularly problematic since searchers may be running resource-intensive algorithms, and TEE compute costs more than traditional compute. The number of containers we can reasonably maintain in parallel directly impacts the system’s operational costs, making pure parallelization an expensive solution.
Another approach is to reuse containers for multiple transactions before resetting. However, safe container reuse typically requires compromises. For example, builders could bundle transactions together rather than processing them individually, but that would unnecessarily restrict transaction ordering possibilities. Whether this type of approach is viable depends heavily on the context in which the sandbox is being used.
Managing External Data
Aside from these tradeoffs, we also need to find a safe way to provide searchers with access to external data. For example, consider price feeds: searchers require real-time token exchange rates from centralized exchanges to identify arbitrage opportunities. Unlike on-chain exchange data that arrives in discrete blocks, these price feeds update continuously, providing a time-sensitive information advantage that can be incorporated into many MEV strategies.
Searchers’ ephemeral containers cannot directly access the internet, as doing so would create channels for data exfiltration. Instead, we need a dual-environment architecture where one persistent container continuously fetches and processes data, populating a database or message queue that the ephemeral containers can query. However, the data source container must be completely isolated from knowing when ephemeral containers access the shared data store. If the persistent container were able to observe access patterns, it could infer information about incoming transactions and potentially leak this data through its internet connection. Solving this problem requires implementing interfaces where the data source container can populate a shared data store but has no visibility into consumption patterns.
Approaches We Investigated
We’ve already looked into several solutions to these problems:
- Reusable enclaves offer strong security guarantees by leveraging hardware-based TEE features, but they are very complex and come with significant limitations for our use case. Each container restart incurs approximately 100ms of overhead, which may be acceptable for some applications but could impact performance-sensitive strategies. More critically, reusable enclaves are restricted to running WASM binaries rather than full Linux containers, which would significantly degrade the system’s ease of use.
- CRIU (Checkpoint/Restore in Userspace) initially appeared promising for eliminating container startup overhead by checkpointing running processes and restoring them later. However, restoring entire container snapshots still requires around 100ms at a theoretical minimum. Since we need to restart containers anyway to achieve proper isolation, enforcing that searchers design their algorithms with quick initialization is likely more practical than adding the complexity of checkpoint/restore mechanisms. If necessary, searchers can still use CRIU themselves from within the container.
- Process forking delivers excellent performance with sub-millisecond startup times, but creates significant challenges for maintaining the isolation and flexibility that we require. While forking provides memory separation between processes, it becomes extremely difficult to ensure that forked processes cannot interact in ways that compromise security while still giving searchers the freedom to install packages, modify system configurations, and use the full range of Linux tooling they expect. The complexity of properly sandboxing forked processes while maintaining a full development environment likely outweighs the performance benefits.
- Container management software like Podman or Docker operates too slowly for our requirements, with typical startup times measured in seconds. However, their underlying container runtimes—particularly runc and crun—could potentially meet our performance needs if we use them directly. The challenge lies in bypassing the higher-level orchestration layers and unneeded features while maintaining the isolation and security boundaries that container management software usually provides out of the box.
Our investigation points toward leveraging container runtimes directly as the most viable path forward, since they can reach start times of around 10ms. Also, depending on the source of the transactions and the performance requirements, we can further optimize the throughput of this approach by maintaining a pool of pre-booted containers and distributing orderflow to containers in such a way that containers can be safely reused as frequently as possible.
Community Questions
To the broader community: We’re eager to hear about additional approaches we might have overlooked. Are there containerization technologies, process isolation techniques, or virtualization methods that could achieve our performance and security requirements? Beyond the technical implementation, we’re also interested in learning about other use cases where ephemeral execution environments could democratize access to competitive markets. What other scenarios exist where information accumulation creates unfair advantages, and how might this infrastructure help?
To searchers and MEV developers: Understanding your workflow requirements will be crucial for designing the right solution. What would constitute an acceptable user experience for you? Do you absolutely need full container environments with complete filesystem access, or could you work within more constrained execution models if they offered better performance? For those running performance-sensitive strategies, what are your most demanding computational environments, and what level of boot up overhead could you tolerate while still maintaining profitability? Your input on these trade-offs will help us prioritize which technical approaches to pursue first.