Motivation
In a recent work [1], we studied cross-chain arbitrages executed between nine blockchains. As part of our methodology, we collected trading data for activity between September 2023 and August 2024, using Allium [2]. We implemented a query functioning as a trade data collector, with an aggregation and filtering logic for correct accounting when detecting cross-chain arbitrage matches. We further filtered the output of the query internally via our heuristics, and used the final results in our analyses.
In this post, we share the details of our original methodology, reproduce it using a different data source, Dune Analytics [3], and compare the outcomes.
TL;DR
- Dune has data quality similar to Allium for our purposes. Evaluating different heuristics on labeled Dune data yields nearly the same predictive performance metrics as Allium, confirming the validity of the thresholds we determined in our original work.
- Implementing a raw data collector like we did with Allium is possible, but data export costs are too high. Alternatively, we can code most of the matching logic directly on Dune and cut down the number of rows to be exported. However, this imposes a considerable execution time cost, which cannot be optimized/parallelized trivially.
The Original Methodology
Our cross-chain arbitrage detection methodology has three steps:
- Trade data collection using Allium: We collect all trades on the DEXes and aggregators of the studied blockchains during the study period. We apply the following filters, conversions, and aggregations:
- We define a generic token symbol based on the original token (e.g., USDC, USDT → USD)
- We drop the trades where the tokens sold and bought are the same, as this could be a cyclic atomic arbitrage.
- We use a transaction’s first and last swaps to determine the initial input and final output assets and amounts.
- For the intermediate swap steps, we add their amounts to the initial/final tokens traded if the token sold matches the initial input asset or the token bought matches the final output asset. This is needed for accurate accounting as some dexes/aggregators can do multiple swaps to fulfill a trade (e.g., break down a 100 Token A→Token B trade into three swaps with 33.3 Token A → Token B each)
- We use aggregator events over swap events when possible, as the former’s data usually already aggregates the amount of intermediate swaps.
- When there are multiple aggregator events emitted in the same transaction, we take the first one, and:
- Sum up its amount with the amounts from the events with matching input/output assets and belonging to the same aggregator protocol (e.g., multiple 1inch events for doing a WETH→PEPE trade inside the same tx)
- Ignore aggregator events belonging to other protocols
- When there are multiple aggregator events emitted in the same transaction, we take the first one, and:
- Matching: This is the core part of our detection methodology for identifying the pairs of transactions that, when combined, expose a cross-chain arbitrage. For any transaction pair (t_1, t_2), we apply four heuristics:
- H1 (cyclic): the input and output assets of the transactions form a closed loop
- e.g., t_1: WETH→PEPE, t_2: PEPE→WETH
- H2 (marginal-difference): the intermediate amounts differ by at most 0.5%
- e.g., t_1: 0.2 WETH→ 100,000 PEPE, t_2: 100,000 \pm 0.5% PEPE→ 0.25 WETH
- H3 (temporal-window): the time gap between transactions is \leq12s for stablecoin-native pairs and \leq 1h otherwise
- e.g., t_1 (WBTC, WETH) at 12:10:20, t_2 (WETH, WBTC) at 12:10:22
- e.g., t_1 (USDC, OMNI) at 12:10:20, t_2 (OMNI, USDC) at 12:14:20
- Note: The 1h window is more of an upper bound to limit computational work. Empirically, this bound is non-restrictive: ∼79 % of matches occur within 10 minutes, and ∼94 % within 30 minutes, ensuring coverage without introducing artificial links.
- H4 (entity link): the same Externally Owned Account (EOA) submits both transactions, or both first interact with the same MEV contract
- H1 (cyclic): the input and output assets of the transactions form a closed loop
- De-duplication: The matching step can result in the same transaction appearing in multiple candidate pairs. We de-duplicated using a three-level ranking system to find the most likely match for each transaction and drop others. We prioritize the matches with 1. \leq 0.1\% marginal-difference, 2. \leq240s temporal-window, 3. if still tied, order by ascending marginal-difference and, for any exact ties, ascending time gap.
Heuristics validation
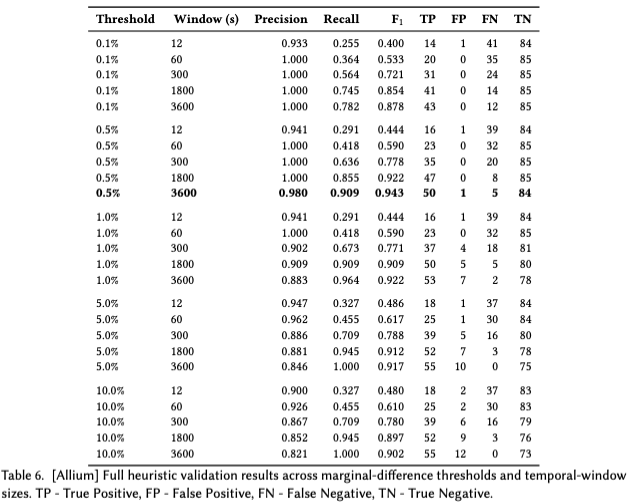
We evaluate the heuristics H2 and H3 against a grid of alternative settings to justify our choices. We sample one hour of trades on seven days and curate a balanced ground-truth set of 140 cross-chain swaps. The table below summarizes precision, recall, F_1, and confusion-matrix counts for all combinations of marginal‑difference thresholds 0.1%-10% and temporal‑window limits 12s-3600s. The pair (0.5, 3600s) strikes the optimal balance, achieving Precision=0.98 and Recall=0.91 (F_1=0.943), keeping genuine arbitrages while filtering spurious ones. More relaxed settings (e.g., 5%, 10% at 3600s) catch marginally more true arbitrages but incur substantially more false matches, and tighter margins (e.g., 0.1%) preserve perfect precision at the cost of a severe recall drop (0.78 even at 3600s), demonstrating that thresholds below 0.5% are too strict.
Dune Reimplementation
Method 1: Raw trade data collection
We initially attempted to recreate the logic we used to run on Allium to collect trade data on Dune, using the similar tables Dune offered (dex.trades, dex_aggregator.trades). We implemented raw_data_collector [4] and tested it on three days.
| Date | # of rows | Runtime with a large engine | Dune export cost (credits) |
|---|---|---|---|
| 2023.09.01 | 1,102,469 | 42s | 749.67 |
| 2024.01.15 | 1,363,442 | 50s | 927.14 |
| 2024.05.15 | 2,156,808 | 52s | 1,466.29 |
- While data coverage and runtimes are pretty good, the export cost is quite high considering that we need to run it for at least 365 days to replicate the original study, and even more for extending it.
- While we can reduce the query cost by concatenating the columns into a single one, this does not make a significant difference.
- Also, some useful fields that Allium had, such as USD amounts for both tokens sold and bought, are missing on Dune.
Method 2: Matching on Dune
To meaningfully cut down the cost of the data export step on Dune, we need to integrate the matching logic into the trade collector script. This way, we would only export the set of candidate matches, a far smaller dataset than the raw trades. For this purpose, we implemented cross_arb_finder [5] and tested it on the same three days.
| Date | # of rows | Runtime with a large engine | Dune export cost (credits) |
|---|---|---|---|
| 2023.09.01 | 704 | 8m | 0.62 |
| 2024.01.15 | 916 | 11m | 0.80 |
| 2024.05.15 | - | 30m (timeout) | - |
| 2024.05.15 (12h-15h) | 268 | 6m | 0.23 |
- While the export costs went down significantly, the runtimes spiked. One option could be to build a pipeline using the API and parallelize the requests. However, a timeout on the Dune side limits the runtime to 30 minutes. Thus, we may need to break down the days into hourly buckets.
- With this data, we only need to perform the de-duplication step of the methodology locally.
Heuristics validation
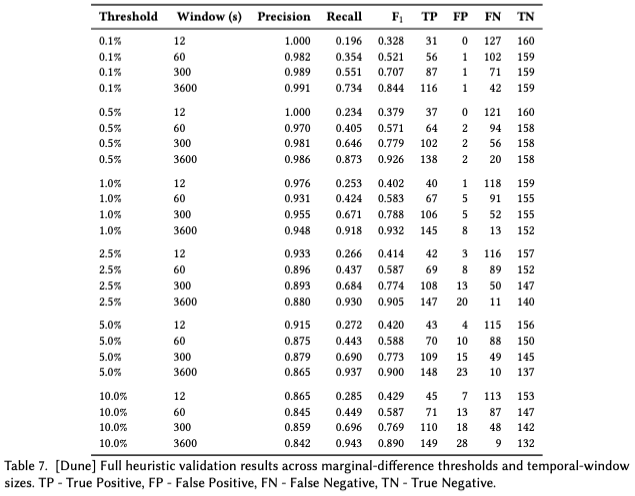
We test the performance of heuristics H2 and H3 on Dune data. We sampled 318 cross-chain swaps over three days and labeled them to create a ground-truth set. The results summarized in the table below show that the (0.5, 3600s) pair again performs decently in terms of precision and F_1 scores, although the recall drops, thus relatively more false negatives, compared to the tests on Allium data (note that these tests are not conducted on the same days and same transactions). Interestingly, 1% threshold at 3600s reaches a higher F_1 score, although again sacrificing precision.
Conclusion
In this document, we describe the methodology we developed for detecting cross-chain arbitrages in our recent paper [1], which utilized data from Allium, and discuss our findings while attempting to reimplement it using Dune. The two databases have matching data coverage, with heuristics performing similarly in predictive power. However, working with Dune is too costly in terms of credits (when trying to export raw trade data) or execution time (when running the matching logic on Dune). Moving forward, we want to build a pipeline to automatically fetch the processed data from Dune, focusing on the shortcomings of the cross_arb_finder script as we find it more scalable than the raw data collection script.
References
[1] Öz, B., Ferreira Torres, C., Schlegel, C., Mazorra, B., Gebele, J., Rezabek, F., & Matthes, F. (2025). Cross-Chain Arbitrage: The Next Frontier of MEV in Decentralized Finance [Preprint]. arXiv. https://arxiv.org/abs/2501.17335
[4] https://dune.com/queries/5486757
[5] https://dune.com/queries/5487097
Extras
We created a small GitHub repo GitHub - boz1/cross-chain-arbs-simple: A simple repo for exploring and analyzing cross‑chain arbitrage data. to play around with the cross-chain arbitrages detected on sample Dune data.