In this post, we explore how block building works in RISE and how its parallel EVM works under the hood.
Quick context before we begin
RISE is an Ethereum Layer 2 blockchain delivering near-instant transactions at unprecedented scale with a projected sub-3ms latency and 100,000+ TPS capacity on mainnet, all secured by Ethereum. Built for CEX-grade performance and full EVM composability, RISE enables builders, traders, and institutions to create and connect to global orderbooks alongside a thriving DeFi ecosystem with ease.
But one might ask, what makes RISE outstanding? Well, Ethereum’s rollup-centric roadmap solved scalability, but introduced new problems: centralized sequencers, weaker interoperability, and fragmented MEV markets. Based sequencing in RISE is an attempt to fix this by moving sequencing back onto Ethereum itself.
What is based sequencing?
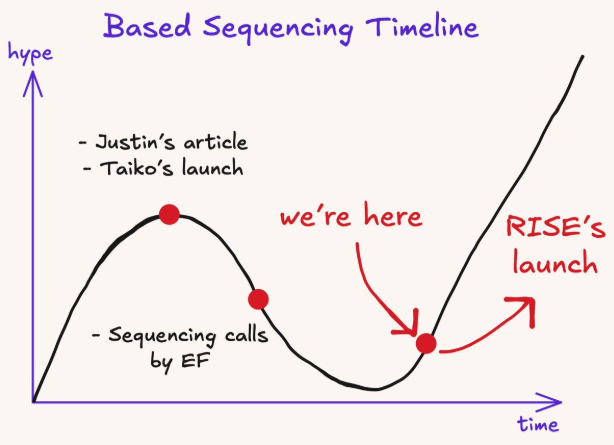
Based sequencing leverages Ethereum L1’s native ordering guarantees instead of relying on a centralized L2 sequencer. Transactions are ordered by Ethereum validators, giving rollups L1-level security, censorship resistance, and composability.
With based preconfirmations, L1 validators can provide fast inclusion guarantees backed by collateral. This allows users to receive near-instant feedback while retaining Ethereum’s security model.
RISE adopts based sequencing to eliminate single-sequencer trust assumption and Inherit Ethereum’s MEV, block-building, and consensus pipeline, amongst others. More so, at full maturity, the sequencing power is derived directly from Ethereum validators, making RISE feel native to L1.
Moving on, based sequencing in Risechain solves the question of who orders transactions. Parallel execution determines how fast they execute.
RISE’s Parallel EVM (pEVM)
RiseChain uses deterministic parallel execution to safely execute non-conflicting transactions simultaneously. By analyzing transaction dependencies ahead of time, RISE can:
- Execute independent transactions in parallel
- Preserve deterministic state transitions
- Maintain full EVM compatibility
This enables massive throughput gains without sacrificing correctness or composability, allowing the chain to reach CEX-scale throughput, Support high-frequency trading and CLOBs, and maintain extremely low latency even under heavy load.
A Peek into RISE Testnet Data
I wrote a 10-minute real-time script to capture RISE testnet data, ensuring that the measurement reflects actual network behavior within a controlled window. This interval provides a snapshot, long enough to capture meaningful trends, fluctuations, and performance patterns, yet short enough to avoid noise from rare or extreme events. By focusing on a precise 10-minute window, the data I collected is synonymous with and directly representative of the testnet network’s behavior in real time.
I then cooked up a quick script to collect the data and then analyzed it to generate charts. Let’s dive into what we discovered.
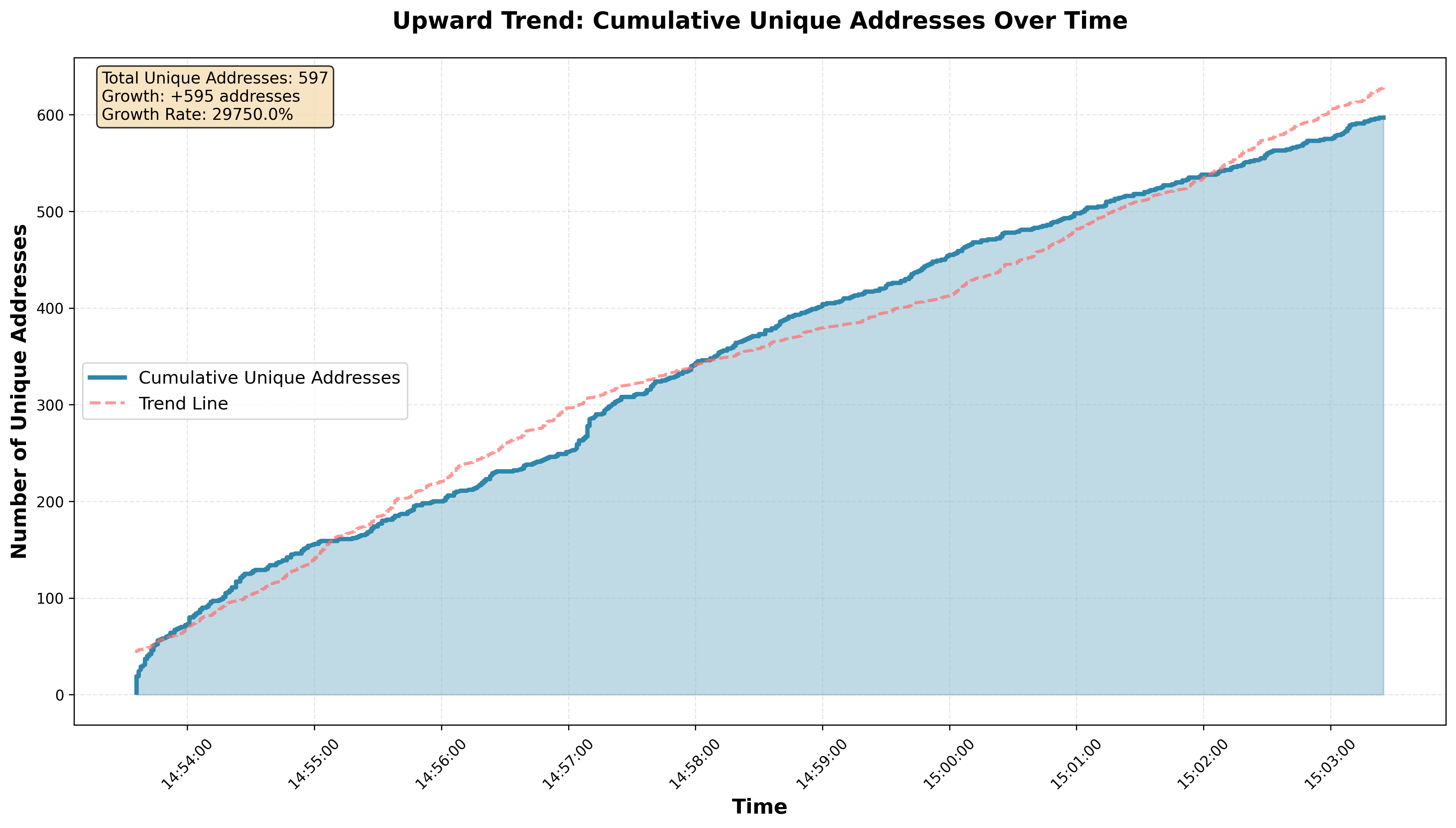
From the chart above in this timeframe, we observe an upward trend in the number of addresses (unique users) on the RISE Testnet.
- Average throughput: 101 TPS
- Active addresses: 1,165
- Transactions per block: ~101, with block sizes around 110 KB, similar to Ethereum
This pattern aligns with expectations, as many transactions on the testnet network are spam in nature. These spam transactions tend to be smaller since they are cheaper to execute.
What and where do these transactions come from for a testnet? In this 10-minute timeframe, we analyzed over 59, 495 transactions and one address ( 0x7fd23f7e57928b2fca8f0eb2d9287073d5db48d9) accounts for 77.3% of all transactions, and the rest are from different addresses. Another data is 97.6% of transactions have zero value, with the average gas price at 16,851.18 wei, for the 1.4% and the 1% of transactions have a zero gas price.
Other charts I was able to generate are:
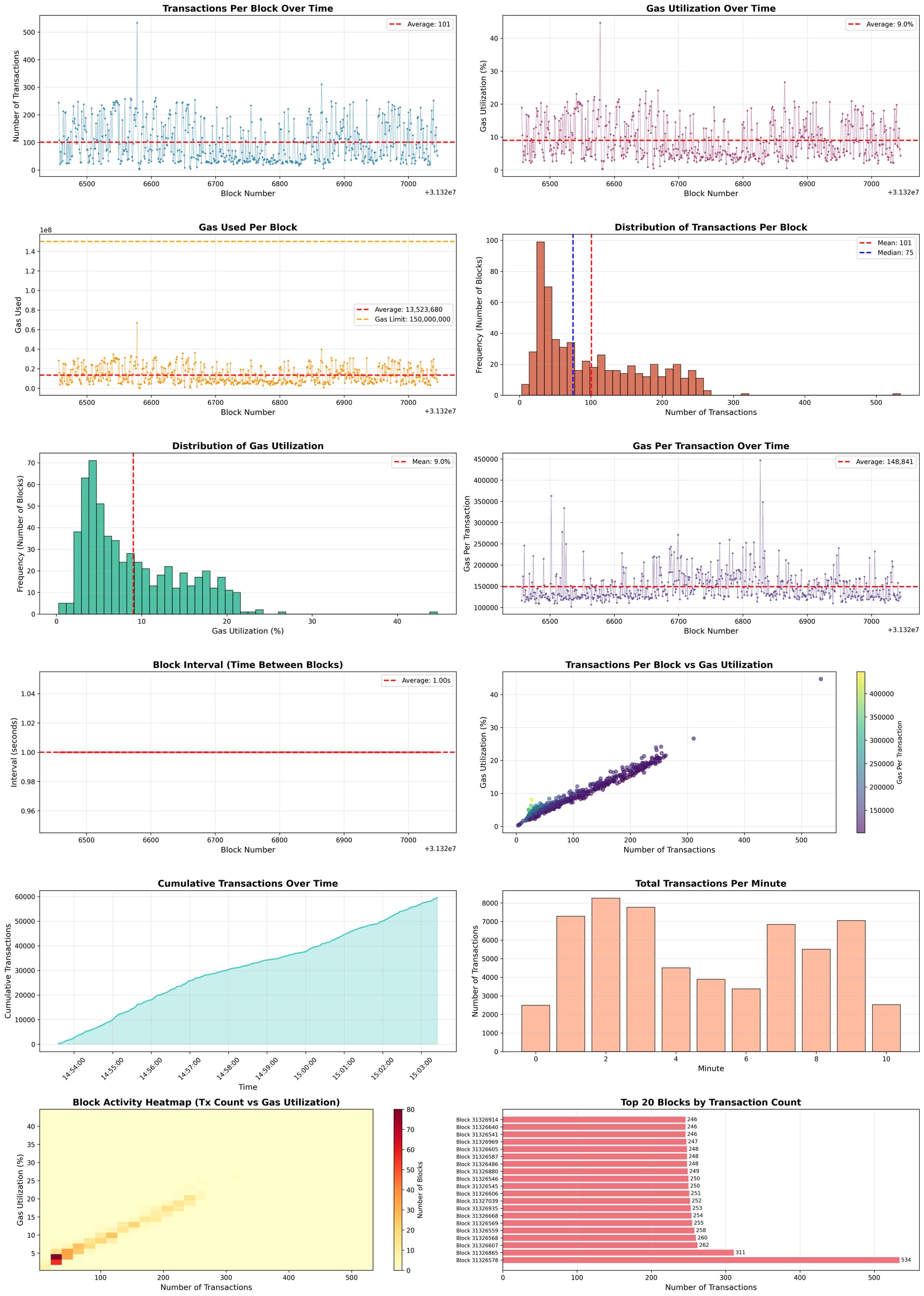
Cool charts, right? Welp, this is not the focus of this post, let’s get into what we are here for: Block Building in RISE
Block Building in RISE
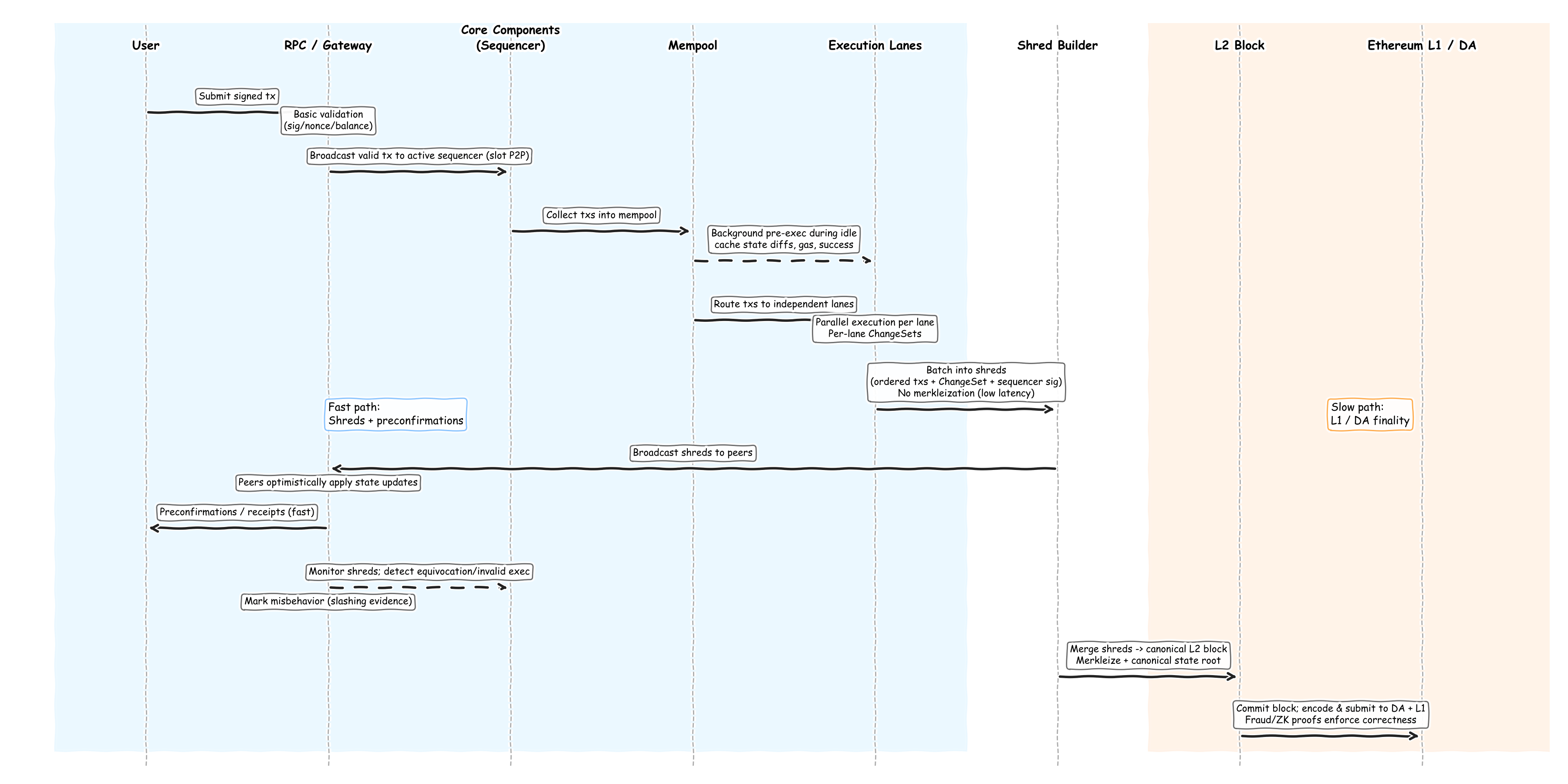
To provide a high-level overview of the block-building process in RISE, I created a diagram that adapts the engineering and research behind RISE into a practical implementation. Let’s walk through it:
- Tx Ingest & Sanity Check: Users submit signed transactions to an RPC node; transactions undergo basic validation and are broadcast via P2P to the sequencer.
- Mempool Pre-Execution (CBP): The sequencer pre-executes pending transactions during idle periods, caching results to reduce latency.
- Shred Construction: Pending transactions are batched into shreds, incremental L2 block fragments, reusing pre-execution results; no merkleization is required, enabling millisecond-level latency.
- Shred Propagation & Early State Update: Shreds are broadcast to peers, who immediately apply changes and preconfirm transactions, providing fast receipts.
- L2 Block Assembly: At the end of the slot or block interval, shreds are combined into a canonical L2 block, which is merkleized and sealed.
- L1/DA Submission: L2 blocks are periodically posted to the DA layer and Ethereum L1 for finality, with fraud or ZK proofs managing dispute and finality windows.
To take this further, I built an architectural demo of the RISE block-building pipeline. In this prototype, transactions are ingested, pre-executed in the mempool, batched into shreds, propagated to peers for early state updates, assembled into L2 blocks, and committed to a local L1 testnet on Anvil. It captures the core mechanics of parallel execution, deterministic lane-based processing, and fast preconfirmations.
Of course, this is a simplified version of the real RISE system. Execution is handled in-process using revm with coarse conflict retries, balances are limited to 64-bit, and full PEVM-style execution, storage-aware scheduling, and signature validation are missing. Shreds and state roots are simplified Merkle structures without proofs, peer networking is local and synchronous, and gateway selection is based on a local hash rather than L1 anchors or rotating gateways. Gas, fees, and persistence are simplified, and there’s no full safety hardening, replay protection, or fraud/ZK proof path.
Even with these limitations, this demo illustrates the high-level flow of RiseChain’s architecture, showing how transactions move through the pipeline, how preconfirmations can accelerate UX, and how shreds are assembled and committed. It’s a stepping stone to understanding the full system and experimenting with parallel execution and L1 integration in a controlled environment.
Here’s the official Demo Video of my implementation.
Nerd Time
This is how I built it:

I built both the L1 and off-chain components of the pipeline. On the L1 side, I wrote four Solidity contracts: BlockCommit to store block commits, GatewayRegistry for gateway registration and selection, Slashing to detect misbehavior, and MockL1 to simulate slot progression. I deployed everything using Foundry and Anvil, encoding and submitting transactions with Cast. A deployment script registers test gateways and exports their addresses for the Rust off-chain system.
The off-chain stack is implemented in Rust, using Tokio for asynchronous execution, k256 for ECDSA signing, and sha3 for Keccak-256 hashing. FlatDB maintains balances, nonces, code, and storage, supporting snapshots, restores, and incremental ChangeSet deltas. Transactions are executed via revm, routed deterministically into lanes by sender hash, with parallel execution on non-conflicting transactions and a final sequential pass for conflicts. Background pre-execution caches head batches (CBP), and shreds are built with executed transactions, a Merkle-ized changeset root, gateway signature, and public key. Peers verify shreds in-process and apply changes for fast preconfirmation simulation.
Block finalization merges all shred deltas, computes a Merkle state root over balances, nonces, code, and storage, and serializes everything via bincode into a BlockCommit structure. L1 commitment is simulated using cast send to call commitBlock on BlockCommit, and gateways are deterministically selected by hashing the registry and slot (a stand-in for L1-based sequencing). Observability is provided via Prometheus and tracing, and historical replay mode benchmarks parallel execution against real Ethereum blocks. This remains a simulation: there’s no real P2P or DA layer, no sparse Merkle/Patricia roots, simplified fee economics, unsigned transaction checks, and balances are capped at u64, but it faithfully demonstrates the mechanics of RiseChain’s block-building and execution pipeline.
Back to our post.
Mom, it’s time to Go Parallel
One feature that truly defines RiseChain’s block-building process is deterministic, sender-based lane routing for parallel EVM execution. Each transaction is assigned to a lane using keccak256(tx.from)% num_lanes, ensuring that transactions from the same sender are executed in order while transactions from different senders are distributed across lanes for parallel processing. Within each lane, transactions execute sequentially, and lanes run concurrently across CPU cores using Rayon. This design reduces cross-lane conflicts and allows the system to retry any overlapping transactions sequentially, ensuring that the final state matches what sequential execution would produce.
The system leverages FlatDB snapshots to compute ChangeSets over balances, nonces, code, and storage. These ChangeSets capture only the state deltas, which are merged efficiently after lane execution. While the lanes themselves are not inherently conflict-free, the combination of deterministic routing and conflict detection ensures reproducibility across nodes. Historical block testing in this demo shows dramatic speedups, orders of magnitude faster than Ethereum’s sequential processing, though actual performance depends on workload characteristics.
This lane-based parallelism integrates seamlessly into the block-building pipeline. Each shred contains executed transactions, the associated ChangeSet, and a signed changeset root. Peers can verify shreds, preconfirm transactions, and merge them into the BlockFinalizer before committing to L1. By combining deterministic ordering, parallel execution, and reproducible state computation, hash-based lane routing transforms RiseChain’s ambitious throughput goals into a high-performance and reliable block-building reality, even within a simplified in-memory prototype.
Deep in the RISE Blocks
When I analyzed the data at the block level, the most striking observation was the consistency of block production and the level of unused capacity in the system. Blocks are produced at a very regular cadence with no gaps, indicating a stable and predictable block-building process. Despite this consistency, gas usage remains low, suggesting the network is operating far below its maximum capacity and has significant room to absorb more activity without congestion.
- Block time: ~1 second (highly regular)
- Total blocks observed: 590 (no missing or empty blocks)
- Block rate: ~54 blocks per minute
- Average gas utilization: 9.02%
- Blocks using <10% gas: 64.1%
- Maximum gas utilization: 44.69%
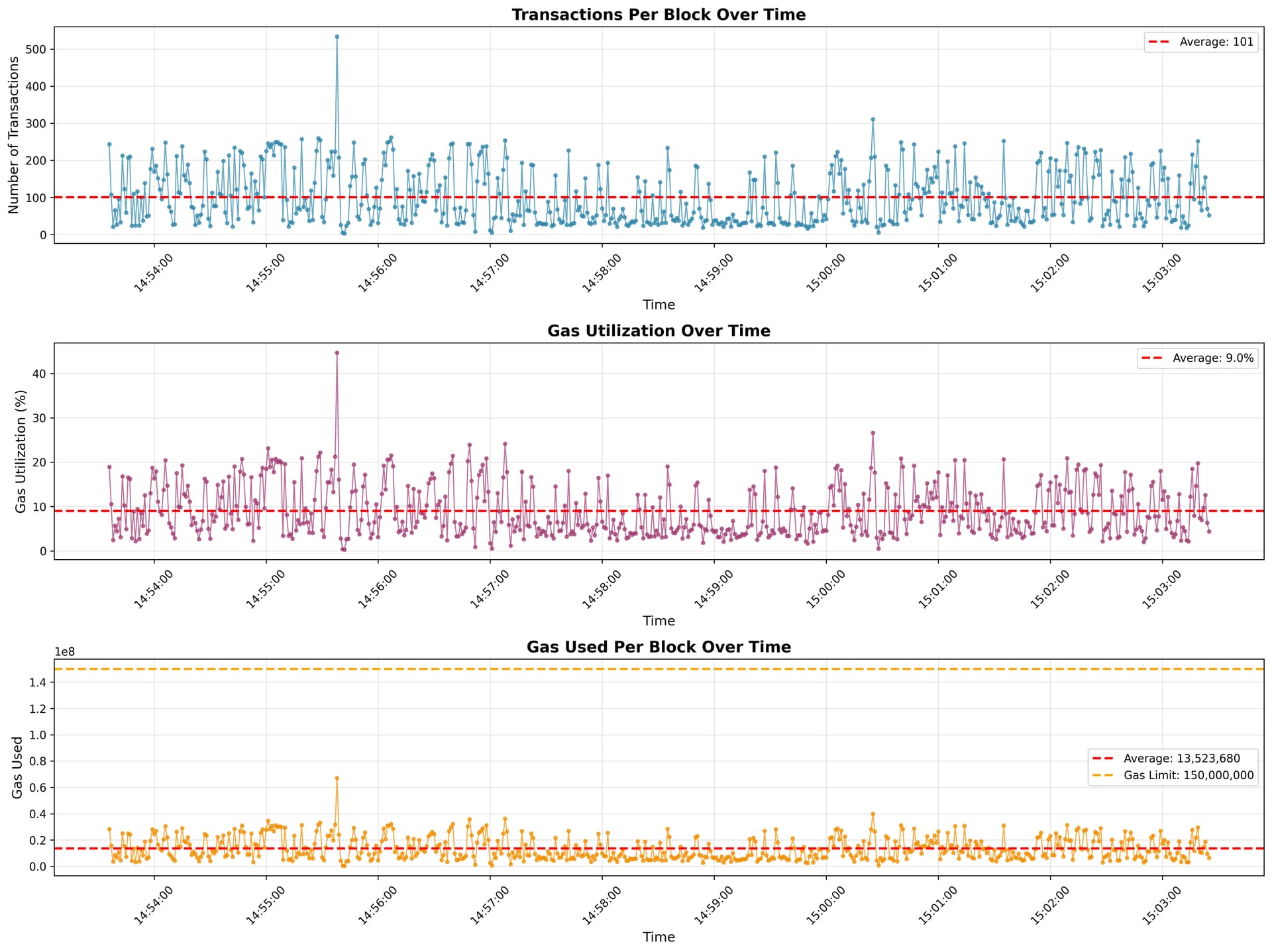
Looking deeper into transaction-level behavior, block activity shows meaningful variation while remaining healthy overall. Most blocks contain a moderate number of transactions, with occasional spikes that are likely driven by spam or stress testing. Even during these bursts, fees remain stable, and blocks stay well below capacity, reinforcing the network’s ability to handle uneven load without degradation.
What Happens Under Real Load
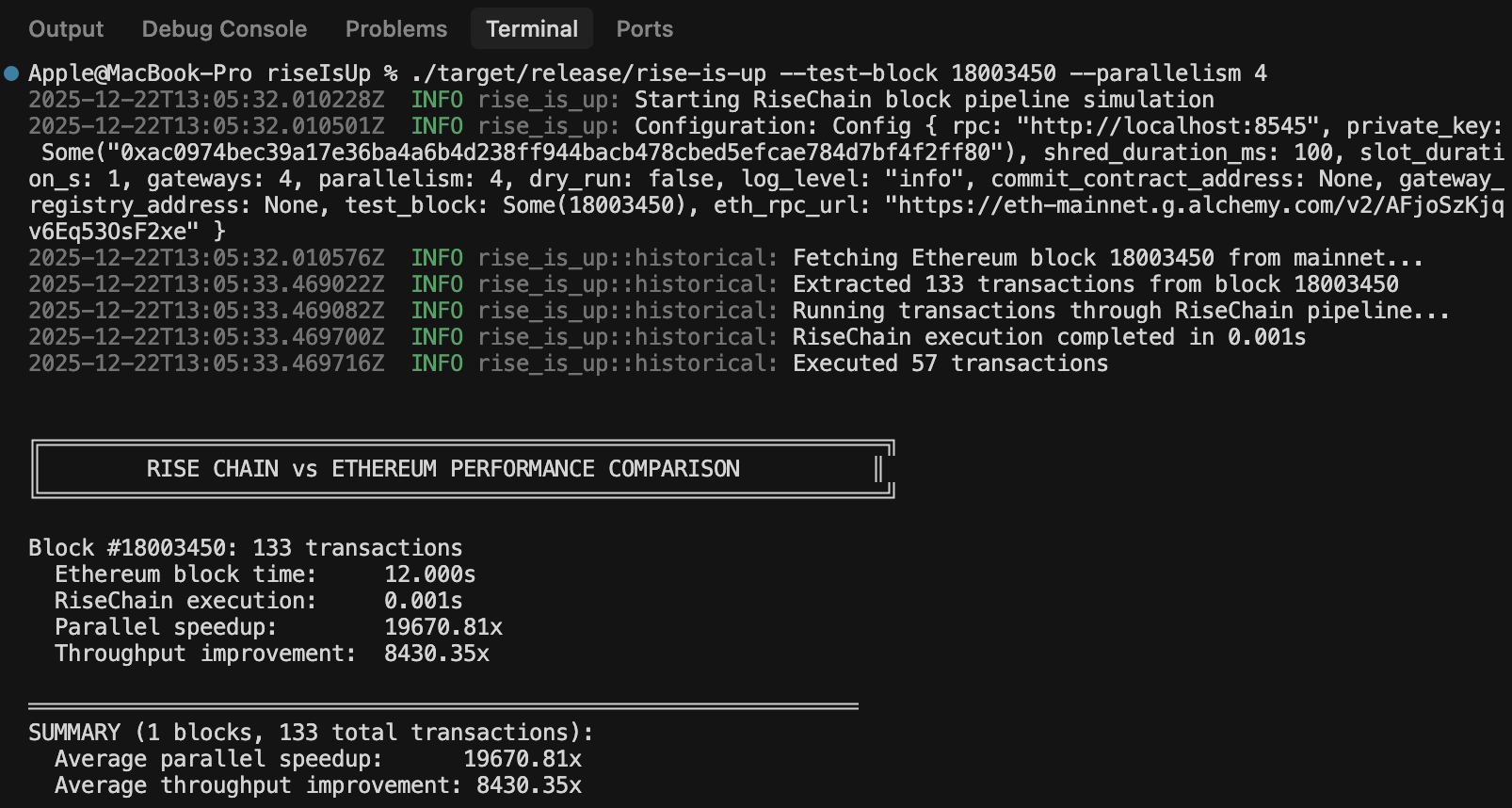
To see how this design behaves under real-world conditions, I battle-tested it against an actual Ethereum mainnet block. Using JSON-RPC, the historical replay tool fetches a full block (e.g., block #18,003,450) along with all included transactions. Each transaction is normalized into the system’s internal Transaction format: addresses are decoded into fixed-size byte arrays, values are bounded to u64 for simulation, and nonces are tracked per sender. This produces a deterministic transaction set ready to be executed by the RiseChain pipeline.
Once ingested, transactions are routed through deterministic, sender-based lane assignment using keccak256(tx.from) % num_lanes. This guarantees that all transactions from the same sender remain in a single lane, preserving nonce ordering, while transactions from different senders are distributed across lanes for parallelism. This routing significantly reduces contention, though it does not eliminate conflicts; different senders may still touch the same recipient or storage slots.
Execution proceeds with lanes running in parallel via Rayon, while transactions within each lane execute sequentially. The engine is revm-backed, performing basic gas and nonce checks against a snapshot of FlatDB (balances, nonces, code, and storage). Write sets are tracked during execution: non-conflicting transactions are accepted immediately, while conflicting ones are retried deterministically in a final sequential pass. Each lane produces a ChangeSet capturing only state deltas, and these ChangeSets are merged additively to produce the final block-level state, matching the result of sequential execution in this simulation.
The primary metric here is execution throughput. The historical replay wraps the full pipeline, from lane assignment through merged ChangeSet, in a high-resolution timer. These figures (e.g., ~610 µs vs ~12 s, ~19,670× speedup) are illustrative and workload-dependent. Actual results vary based on CPU, parallelism level, and transaction access patterns.
Independent transaction mixes yield dramatic speedups, while heavily contended blocks reduce parallel efficiency. Importantly, deterministic routing combined with conflict detection and retry preserves correctness, though this remains a simplified model: it is not a full PEVM conflict-resolution engine and omits signature verification, sparse trie proofs, and full fee economics.
Almost Forgot About RISEx
To take this further, RISEx isn’t a bolt-on application; it’s a direct consequence of RISE’s parallel EVM and low-latency block-building stack. Deterministic parallel execution, driven by hash-based lane routing and continuous pre-execution (CBP), lets RISEx process orderflow concurrently while preserving strict per-sender ordering. That property is non-negotiable for an orderbook (nonce and order sequence must be exact), yet it still enables sub-3 ms execution targets under realistic load.
On the block-building side, shred-based construction keeps latency tight. Instead of waiting for a fully sealed block, RISEx benefits from incremental shreds carrying preconfirmed state deltas. Peers can apply these deltas immediately, so order acknowledgements and book updates propagate as soon as execution completes, not at the end of the slot. This is what allows the system to feel responsive without sacrificing determinism.
Fast finalization then closes the loop. Sub-50 ms slots and frequent, merklized state commitments give RISEx a predictable cadence for marks and settlement, which is essential for tight spreads and consistent pricing. Because all of this happens on a single shared EVM state, RISEx orderbooks can synchronously compose with AMMs, lending markets, and vaults in-block, unlocking shared liquidity and capital efficiency that isolated app-chains or rollups simply can’t offer.
Finally, verifiability remains first-class. Orders live fully on-chain, state transitions are merklized, and signatures make light verification possible. Fraud and slashing paths can backstop gateway behavior, ensuring that low latency doesn’t come at the cost of trust.
I had fun doing this
Hey, I had fun doing this. Feel free to reach out to me, critique, and share your thoughts on my research. Have fun, see you around !!!
Bye-bye.