Summary
This Flashbots Research Proposal (FRP) introduces a novel mechanism for achieving atomic cross-rollup arbitrage between rollups (e.g. Optimism Mainnet and Base) by leveraging a shared infra coordinating with both rollups’ sequencers. Our hypothesis is that a coordinator employing state lock auctions (as proposed by State Lock Auctions – Towards Collaborative Block Building), can orchestrate cross-domain MEV bundles that execute atomically (all-or-nothing) across two rollups. This would eliminate the risks inherent to today’s non-atomic, asynchronous arbitrage strategies while preserving overall throughput and fairness on each rollup.
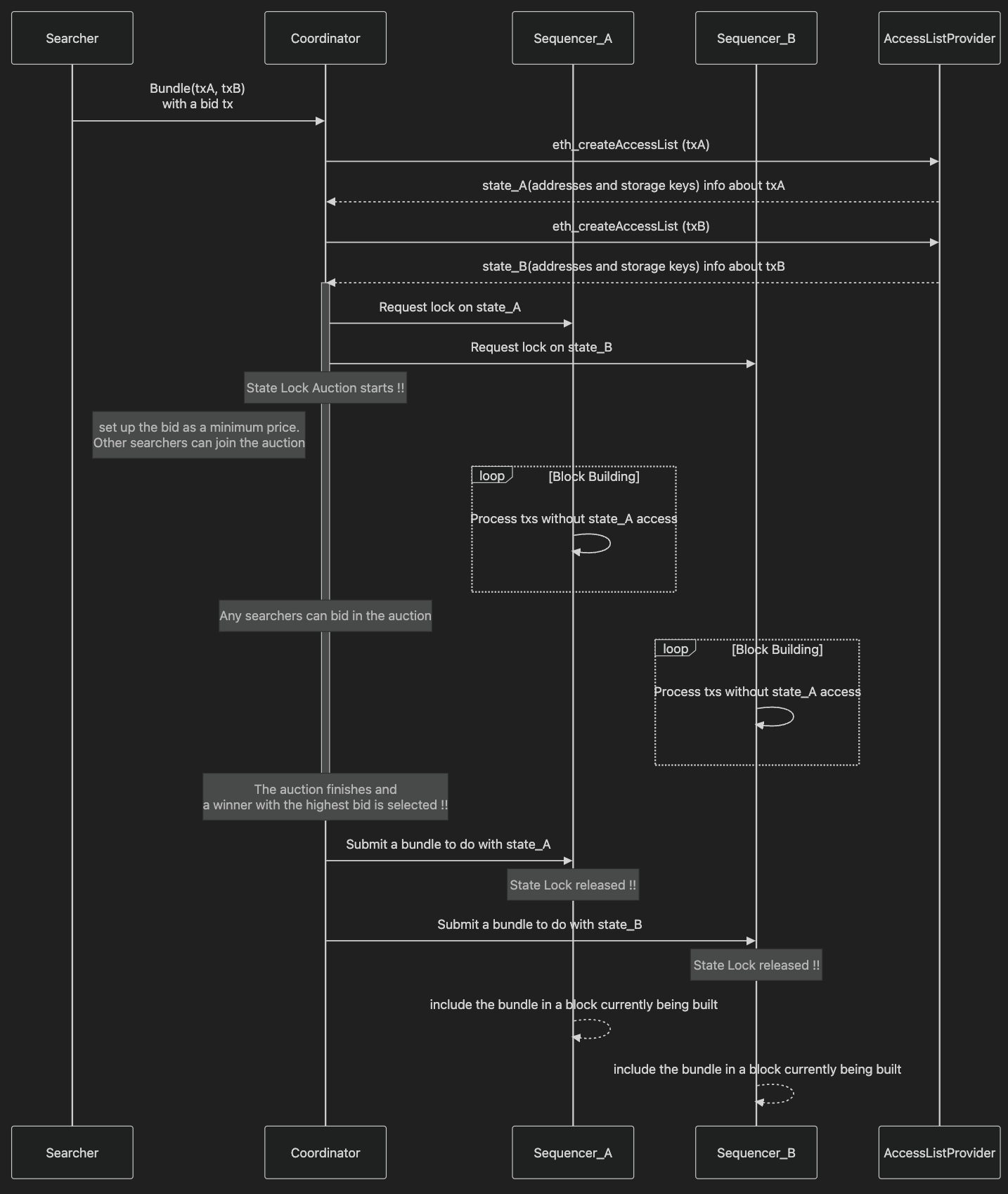
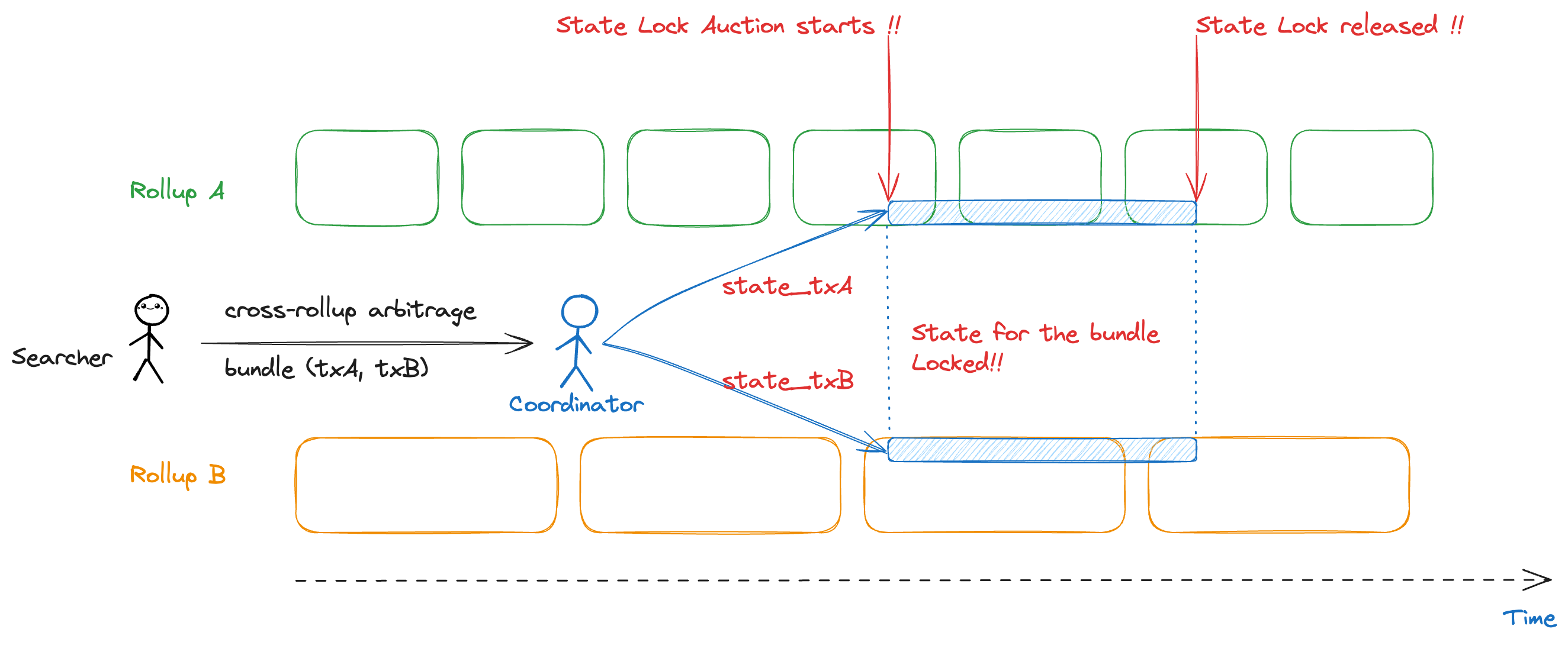
In the proposed design, the coordinator runs an open auction for state locks on the relevant portions of each rollup’s state that the arbitrage transactions (tx_A on Rollup A and tx_B on Rollup B) will touch. Searchers bid for the exclusive right to atomically execute an arbitrage across both domains (or either of them separately). The highest bidder’s bundle is granted locks on those state segments on each rollup for the next block, and their transactions are inserted (by the sequencers in coordination with the builder) into each rollup’s block such that either both execute or neither does. This cross-domain state locking mechanism ensures no other transaction can interfere with the targeted Uniswap pools or other contracts during the lock, enabling atomic execution: the arbitrage executes in full on both rollups or not at all. The coordinator collects the bids as fees, creating a new revenue model aligned with MEV extraction.
Our methodology will involve designing and prototyping this coordinating protocol, using EIP-2930 access lists and Trusted Execution Environments (TEEs) to manage state access and transaction privacy. Access lists allow the searcher’s transactions to explicitly declare which addresses and storage slots they will access, which the builder uses to know exactly which state to lock on each rollup. TEEs (enclaves) will be used so that searchers can submit their arbitrage transactions privately; the enclave can output the access list (state summary) for auction without revealing the transaction’s details, providing secure and transparent extraction of access lists. We will evaluate limitations such as pricing the state lock (to deter abuse) and ensuring liveness/censorship-resistance.
If successful, this approach has significant implications: it would mitigate slippage and race conditions in cross-rollup trading, reduce wasted gas on reverted cross-chain arbitrage attempts, and unlock more efficient price alignment between rollups without requiring full L1 synchronization. It extends the state-of-the-art in MEV auction design (per prior single-domain state lock proposals) to a multi-domain context, potentially informing the design of future shared sequencing protocols for atomic cross-chain execution. By coordinating two otherwise independent sequencers via a market mechanism, we hypothesize that cross-domain MEV can be captured securely without degrading throughput on either chain. This proposal outlines the motivation, design, and research plan to validate this mechanism, including a representative use case of a Uniswap arbitrage between Optimism and Base.
Background and Problem Statement
Cross-Rollup Arbitrage Today: With the rise of multiple Layer-2 rollups, liquidity and trading opportunities are fragmented across domains. Price discrepancies frequently arise between equivalent pools on different rollups (e.g. a WETH/USDC pair on Optimism vs the same pair on Base), offering arbitrage opportunities. However, executing an arbitrage across two rollups is currently non-atomic and asynchronous. A trader must typically execute one leg of the trade on one rollup, then separately execute the second leg on the other rollup, often by listening for an event or using a relayer to trigger the second transaction. There is no guarantee both legs succeed or that they occur back-to-back. In practice, this lack of atomicity introduces several problems:
- Execution Risk & Slippage: If one leg of the arbitrage executes without the other, the arbitrageur is left with an unhedged position. For example, they might buy token A on Optimism expecting to sell it on Base, but if the Base transaction fails, they now hold extra token A and could incur a loss if its price moves. Even if both eventually execute, the price on the second rollup may have slipped by the time of execution, eroding profits or causing a revert due to slippage limits.
- Latency and Race Conditions: Asynchronous cross-chain trades have inherent latency – the time it takes to confirm the first transaction and relay a message to start the second. During this delay, market conditions can change or competing arbitrage bots can react. This often forces arbitrageurs to “race” to be faster than competitors and price movements, or to inflate their bids to outpace others in each domain’s mempool. High latency lowers the chance of successfully capturing the price discrepancy.
- Solver/Relayer Exposure: Because atomic execution isn’t available, traders sometimes rely on third-party “solvers” or fast relayers to execute the second leg upon seeing the first leg. This exposes the strategy to those parties – who might front-run or censor the trade – and adds complexity and trust assumptions. In essence, arbitrageurs must reveal their intent to some extent (via the first transaction or via coordination with a relayer), inviting adversarial interference.
- Inefficient Execution (Reverts & Cost): Many cross-domain arbitrage attempts result in one transaction reverting if the other leg fails or if the opportunity vanishes. Searchers often compensate by shotgun submitting many transactions or cancels, accepting that most will revert. This leads to wasted block space and gas. Recent research indicates that on L2s, a huge number of arbitrage opportunities remain unexploited or delayed due to these difficulties. In fact, a majority of arbitrage volume in Ethereum and L2 ecosystems comes from such non-atomic (cross-domain or CEX-DEX) arbitrage, which carries these inefficiencies.
Overall, the current state-of-the-art for cross-rollup arbitrage is suboptimal. Liquidity remains fragmented because there is no secure, fast way to unify price action across rollups the way arbitrage on a single chain can unify prices between DEXes. The motivation for this proposal is to remove the uncertainty and risk from cross-rollup arbitrage by making it atomic: either both trades execute in lockstep or none do. If arbitrageurs can rely on atomic execution, they can confidently take larger positions with lower risk premiums, leading to tighter price alignment between rollups and more efficient markets.
Towards Atomic Cross-Rollup Execution: Achieving atomicity across different chains or rollups is challenging because each domain has its own independent sequencer and block production. A naive solution is a shared infra that orders transactions for multiple rollups together. ( Shared sequencer as envisioned in the Optimism “Superchain” roadmap) Indeed, Optimism developers have noted that “synchronous cross-chain messaging and atomic cross-chain interactions” could be enabled by a shared sequencing protocol operating on both chains. In such a design, the sequencers of chain A and chain B would coordinate on including a cross-chain bundle in the same block on both sides, and only charge fees if both transactions are included successfully. This concept shifts the synchronization risk away from the user and requires the sequencers to come to consensus on cross-domain orderings.
However, full shared sequencing requires significant changes to the rollup protocol and consensus, and may introduce complexity or new failure modes if not carefully designed. In the interim (and even as a complement to shared sequencing), we propose a more incremental, builder-centric approach: use a coordinator that works with existing sequencers to mimic atomic inclusion through MEV techniques. In Ethereum’s Proposer-Builder Separation (PBS) model, block builders assemble blocks given user transactions and bids. We extend this concept across chains by introducing a coordinator that can assemble two blocks (one per rollup) with a synchronized arbitrage bundle in them. Crucially, we employ the idea of state lock auctions to ensure that the arbitrage bundle can execute without interference on both chains.
State Lock Auctions (Single-Domain Recap): The concept of state lock auctions was recently proposed by Flashbots researchers as a way to manage high-frequency, single-tx arbitrages at the top of blocks. Instead of searchers privately bribing block builders or sequencers with opaque bids (leading to a vertical integration arms race), the idea is to create an open auction for the right to “lock” specific portions of the state for exclusive use in the next block. In this model, searchers submit a bid along with a description of which state their transaction will touch (an access list), and if they win, that transaction is guaranteed to be executed affecting that state, while no other transaction in that block can touch it.
- Key properties of this design include:
- Exclusivity and Safety: Only the winning transaction can modify the locked state in that block, preventing any conflicting trades. This is especially important for arbitrage on a DEX pool – it guarantees no one else can access the same pool in that block before the arbitrage completes, avoiding collision or partial fills.
- Visibility of Locked State: The set of addresses/storage being locked is made visible (after the auction) to block builders. This transparency lets the builder (or other partial block builders) confidently fill the rest of the block with other transactions that don’t touch the locked state, maintaining throughput and enabling “collaborative” block building. Essentially, the builder knows which areas of state are safe to use for other transactions.
- Bid Competition & Pricing: Searchers bid in an open first-price auction for the lock. A minimal reserve price can be set proportional to the size of the state accessed (e.g. a base cost per storage slot touched) to discourage locking large swaths of state cheaply (squatting resistance). The highest bidder wins, paying their bid via a dedicated payment transaction included in the block. This payment typically goes to the block proposer (e.g. the validator or sequencer) as revenue.
- Transactional Integrity: The searcher provides their actual arbitrage transaction (call it
tx_state) in advance, along with an assurance (via simulation and using Ethereum’s EIP-2930 access list mechanism) that this transaction will only touch the specified state. The builder/relay can enforce that the includedtx_stateindeed has an access list exactly matching the locked state. The searcher can also be allowed to update certain parameters of the transaction after winning (e.g. adjust swap amounts) as long as the access list (i.e. the affected state) does not change. This allows flexibility to react to price changes between the auction time and execution, as long as no new state is accessed (thus preserving the lock’s validity). - Guaranteed Payment & Finality: Whether or not the winning transaction ultimately yields profit or even executes, the lock payment is guaranteed to be made (to prevent griefing by winning and then not following through). If the searcher wins the auction but fails to provide a valid transaction that matches the state or reverts, the block still includes the payment (so the builder/proposer is compensated) and the system may revert or skip the state-changing transaction. This incentivizes honest bidding and discourages frivolous locks. (In practice, we expect the builder will only include a
tx_statethat has been verified to succeed on the locked state.)
This mechanism has been sketched out for a single domain (one block) context. Our insight is that we can extend state lock auctions to multiple domains (two rollups) simultaneously. The problem statement we address is: Can we enable atomic arbitrage across two rollups by coordinating their block production through a coordinator that locks the relevant state on each rollup via auction? We need to ensure that this can be done without protocol-level changes to the rollups (leveraging existing mechanisms like block building and access lists), and that it does not degrade the normal operations of each rollup beyond the specific state segments being locked for arbitrage. We also need to ensure the solution is economically sound (profitable for participants) and secure (no new vectors for abuse beyond acceptable levels).
In summary, the goal is to research and develop a mechanism where the highest-value cross-rollup arbitrage bundle is executed atomically, with the blessing of both rollup sequencers, and all other arbitrageurs or conflicting transactions are excluded from those particular state areas for that block. By doing so, we hope to drastically improve upon the non-atomic arbitrage model (eliminating its drawbacks like slippage and latency race) and to pave the way for more unified liquidity across different rollups. This proposal will explore the design in detail and answer open questions such as: How to run a dual-chain state auction efficiently? How to split the payment between two chains’ proposers? What are the failure modes (e.g. one side of the trade reverting) and how to handle them? How to prevent denial-of-service or griefing by bidding to lock state on multiple chains without intention to execute? The following sections outline our approach to tackling these questions and the deliverables we plan to produce.